
What Is a Data Ingestion Pipeline? How It Powers Modern Data Systems
Ready to transform your data strategy with cutting-edge solutions?
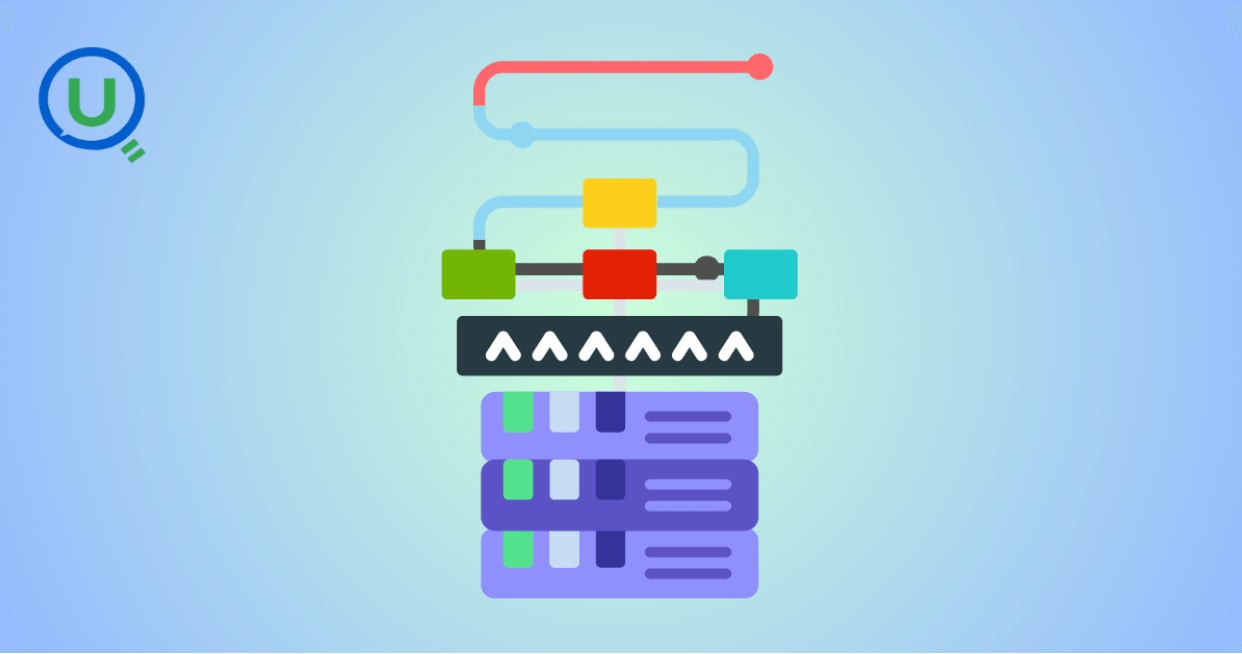
Every interaction in today’s digital world—from online shopping carts and mobile app events to IoT sensor readings and streaming logs—creates data that needs to be captured, processed, and acted upon. But capturing raw data is just the start. For organizations to extract value, insights, and intelligence, they need a robust data ingestion pipeline—an automated, scalable, and reliable process that bridges the gap between data sources and downstream analytics systems.
A data ingestion pipeline ensures that data moves smoothly from collection points into centralized storage or analytics platforms like data warehouses, lakes, or real-time streams. It handles tasks like format conversion, error detection, data validation, and load balancing, enabling organizations to build trusted, high-quality data foundations.
In this blog, we'll explore what a data ingestion pipeline truly is, why it’s essential for modern enterprises, and what its core components look like. We'll also highlight key benefits and best practices to help you design pipelines that power fast, accurate decision-making across your organization.
Understanding what a data ingestion pipeline is
A data ingestion pipeline refers to a sequence of processes and tools that move data from various sources into your target systems, in a structured, consistent, and timely manner. But this deceptively simple definition hides several crucial design and engineering challenges:
Multiple types of ingestion
Pipelines can support different ingestion modes depending on business requirements:
Batch ingestion: Moves larger chunks of data periodically (e.g., hourly, daily).
Micro-batch: Handles data in smaller (seconds to minutes) intervals.
Stream ingestion: Captures events in real time, ideal for live analytics and monitoring.
Source heterogeneity
Modern Pipelines must connect to myriad sources:
Databases (SQL, NoSQL)
Cloud storage systems (S3, Google Cloud Storage, Azure Blob)
SaaS APIs (Salesforce, Stripe, HubSpot)
Logs and message queues (Kafka, Amazon Kinesis, RabbitMQ)
IoT and sensor feeds
Essential transformations
Ingestion pipelines often perform light transformations to ensure data quality and consistency:
Parsing raw formats (CSV, JSON, XML)
Timestamp normalization
Field mapping and schema harmonization
Basic validation and error handling
Heavy transformations are typically separated into downstream pipelines to maintain ingestion simplicity.
Delivery to multiple destinations
Once ingested and lightly processed, data must land in various systems:
Data lakes (raw data)
Data warehouses (curated, analyzed data)
Stream processors (clickstream, alerts)
Application databases (fraud detection, personalization)
Pipeline orchestration and monitoring
A robust pipeline tracks:
Job scheduling and dependencies
Success/failure alerts
Message replays and fault tolerance
Back pressure handling
Scalability under load
Together, these components define a powerful data ingestion pipeline designed to support modern analytics, operational systems, and machine learning platforms.
Why is a data ingestion pipeline essential for modern data architectures?
The importance of a data ingestion pipeline extends far beyond simply transporting data—it plays a strategic role in enabling real-time analytics, data-driven decision-making, and business agility. Let’s unpack why it’s essential:
Enabling near-real-time insights
Without a dedicated ingestion layer, data may trickle into analytics systems with hours or days of delay. In contrast:
Financial firms can monitor fraud indicators as they happen
Retailers can respond to inventory anomalies in real time
Platforms can deliver personalized recommendations immediately
A data ingestion pipeline reduces latency, enabling faster insights and actions.
Ensuring data reliability and trust
Pipelines enforce consistent formats, validate incoming payloads, and flag corrupted data:
Rejecting partial or malformed records
Logging missing values or inconsistent schemas
Retrying or quarantining failed streams
This builds trust in the data foundation used by analysts, AI models, and executives.
Supporting scalable data growth
With millions of sources and billions of events, data volume can explode:
A streaming pipeline connects to hundreds of IoT devices
Daily product interactions generate massive log volumes
Enterprise apps produce complex API streams
A well-architected data ingestion pipeline scales horizontally to handle data spikes and long-term growth.
Reducing engineering debt and duplication
Without centralized ingestion, teams often build custom connectors:
Each department writes its own scripts
Duplicate logic and inconsistent schemas spread across teams
Maintenance becomes a bottleneck as data sources multiply
A unified pipeline consolidates ingestion logic, schemas, and error handling, cutting duplication and improving maintainability.
Enabling multi-destination delivery
Data often needs to land in several places for different use cases:
Raw landing zones for archive and lineage tracing
Curated tables for BI/SQL queries
Stream processors for dashboards or ML
Data marts for department-specific nee
A pipeline that supports fan-out delivery ensures consistent ingestion across all destinations with a single source of truth.
Core components and stages of a data ingestion pipeline
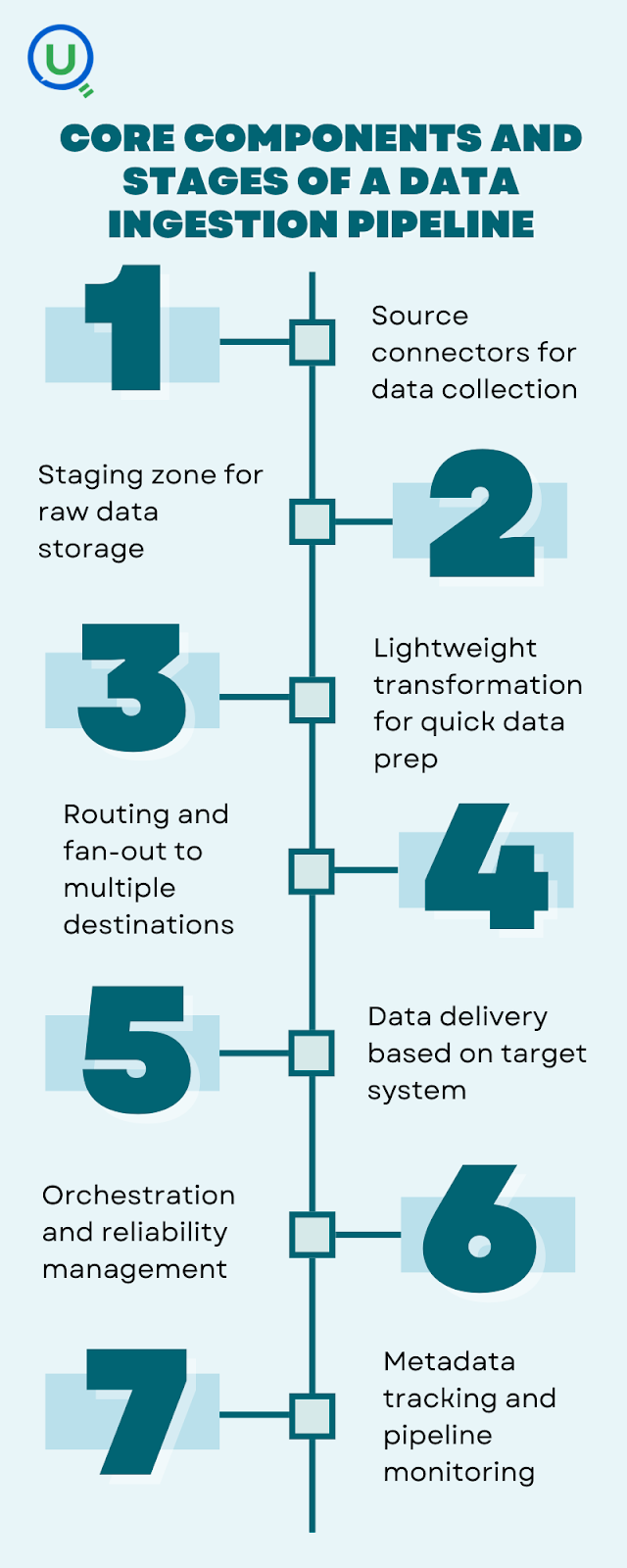
Breaking down a comprehensive data ingestion pipeline into its constituent parts helps in building reliable systems. Let’s map out the key stages:
Source connectors
Connectors initiate the flow and fetch data, using:
JDBC/ODBC for databases
API keys and HTTP calls for SaaS endpoints
Polling, CDC, or log consumption for real-time DB changes
Filesystem watchers for new files in storage
These connectors must support parallelization and secure credentials.
Staging or raw zone
Raw or staging zones serve as temporary landing areas:
Raw data retention for lineage and auditinz
Replay buffer to recover from downstream failures
Time-travel support for delayed pipelines
Storage methods vary: object stores for files, collections for events, or internal messaging systems.
Lightweight transformation
At ingestion time, pipelines clean and prep data slightly:
Data parsing (CSV, JSON decoding)
Schema enforcement and timestamp formatting
Tagging records with metadata (ingest time, source)
Basic cleansing (trimming whitespace, date formats)
Light transforms streamline data without overloading the pipeline.
Routing and fan-out
A robust ingestion pipeline determines where data goes:
Writes to raw zones for archival
Routes to ingest-friendly transformation systems
Publishes to stream subscribers for real-time needs
Loads into analytical databases or lakes
Fan-out routing ensures seamless delivery to multiple targets.
Delivery to destination
How data reaches its final destination depends on structure:
Batch-loading into warehouse tables with bulk API
Stream-loading into platforms like Kinesis or Pub/Sub
Appending to data lake folders partitioned by time or category
Each method requires orchestration to maintain order, retries, and consistency.
Orchestration and reliability layer
Behind the scenes, pipelines rely on control:
Workflow schedulers (Airflow, Prefect, native schedulers)
Dependency graphs to preserve order
Retries and idempotency markers
Instrumented logging for observability
Metrics tracking for throughput, latency, errors
This failsafe layer ensures pipelines run smoothly at scale.
Metadata and monitoring
Advanced ingestion platforms also:
Capture data provenance (source, time, version)
Track schema evolution and incompatibilities
Communicate data freshness statistics
Alert on performance or error issues
Monitoring interfaces keep engineers informed and pipelines healthy.
Best practices for designing a data ingestion pipeline
Building an effective data ingestion pipeline requires careful planning, design, and ongoing operations. Here are best practices to guide the process:
Treat ingestion as first-class data infrastructure
Many treat ingestion pipelines as afterthoughts. Instead:
Define SLAs for freshness and reliability
Ensure connectors are versioned and tested
Monitor ingestion health with dashboards and alerts
Handle schema evolution gracefully
Data sources evolve over time:
Detect structural changes automatically
Apply schema registry for consistency
Support backward-compatible upgrades
Support replay and recovery
Data pipelines should be resilient:
Persist raw messages for retries
Use offsets or bookmarks to resume from failure point
Build idempotent sinks to avoid duplicates
Separate ingestion from transformation
Avoid tightly coupling ingestion logic with business logic:
Keep ingestion shallow and independent
Do heavy transformations downstream
Simplifies pipeline debugging and evolution
Automate deployment and version control
Infrastructure as code is critical:
Store schemas and connectors in source control
Use CI/CD for pipeline deployment
Maintain changelogs with audit trails
Secure sensitive data
Security must be built in:
Utilize encryption in transit and at rest
Rotate credentials and use least privilege
Mask or redact PII during ingestion
Log access and transformations
Implement observability from day one
Track key metrics:
Throughput (records/sec)
Latency (end-to-end delay)
Error rate and failure types
Resource utilization
Set alerts to act before issues escalate.
Plan for burst and scale
Data loads can vary significantly:
Design connectors for elastic scaling
Use auto-scaling clusters (Kubernetes, serverless, managed)
Buffer data during peak ingest windows
Document and govern ingestion paths
As systems grow:
Catalog which sources feed which tables
Track sink dependencies by team
Auto-generate documentation (e.g., using OpenAPI, schemas)
Powering modern use cases with data ingestion pipelines
data ingestion pipeline systems enable a wide range of strategic initiatives:
Real-time analytics and monitoring: Fresh dashboards, anomaly detection
Personalization engines: Live user updates, customized experiences
Machine learning and ai: Feeding training data and inference inputs
Governance and compliance: Lineage logs, raw data retention
Archival and backup: Raw storage with efficient retrieval
These systems become the mission-critical vehicles that drive tomorrow’s intelligent systems.
Choosing the right technology for your data ingestion pipeline
Since each organization is unique, the pipeline tech you choose depends on factors like purpose, scale, and ecosystem.
Open-source vs managed services
Open-source (Kafka, NiFi, Airbyte) offers customization and ownership
Managed services (Fivetran, Stitch, AWS Data Migration, Azure Data Factory) offer low maintenance and quick onboarding
Batch vs streaming support
Batch-focused tools (Sqoop, DBT + Staging) fit non-critical delay use cases
Streaming tools (Kafka Connect, Flink, Kinesis, Pub/Sub) enable real-time systems
Code-based vs low-code
Code-first tools (Python, Spark) offer flexibility for complex logic
Visual tools allow non-engineers to participate (e.g., Azure Data Factory pipelines)
Ecosystem integration
Tools should seamlessly connect to your data lake, warehouse, or lakehouse
Look for native support to reduce maintenance (e.g., Snowflake Streaming, GCS Connectors)
Scalability and reliability
Choose platforms built for your scale:
Kubernetes for containerized scaling
Serverless for burst-heavy workloads
Multi-region support for data locality
Cost model
Some platforms charge per row, volume, or connector usage
Estimate growth and evaluate TCO across ingestion and storage costs
Measuring success in your data ingestion pipeline
To measure how well a data ingestion pipeline performs, track:
Latency: Time from event generation to landing
Throughput: Records processed per second/minute
Error rate: Failed vs successful record counts
Uptime: Pipeline availability
Resource efficiency: CPU, memory, and storage usage
Freshness: Data staleness windows or timestamps
These KPIs indicate health and highlight when tuning or scaling is needed.
Final thoughts
A data ingestion pipeline is the critical engine that fuels modern data systems. From capture and staging to delivery and monitoring, these pipelines ensure that data flows reliably, accurately, and at the speed that business demands. Without a solid ingestion layer, analytics and AI initiatives fall short—delayed, inconsistent, or fragmented.
Building a robust ingestion pipeline involves thoughtful design, rigorous monitoring, scalable infrastructure, and tight governance. By applying best practices—like separating transformation, enabling replay, and securing data—you can build systems that support real-time analytics, personalization, regulatory compliance, and more.
Whether you use cloud managed services, open-source frameworks, or hybrid architectures, the goal remains the same: enable data to move seamlessly from source to insight, underpinning every critical decision and intelligent system in your organization.
Instead of building your ingestion infrastructure from scratch, partner with a team that understands the nuances of scalable data systems. Enqurious works with forward-thinking organizations to design, implement, and optimize reliable data ingestion pipelines tailored to their goals.
Talk to our expert today and unlock the full potential of your data.
Ready to Experience the Future of Data?
You Might Also Like
Learn the essential role of ETL (Extract, Transform, Load) in data engineering. Understand the three phases of ETL, its benefits, and how to implement effective ETL pipelines using modern tools and strategies for better decision-making, scalability, and data quality.

Discover why data orchestration and analysis are essential for modern data systems. Learn how automation tools streamline data workflows, boost insights, and scale with your business

Discover the top 15 data warehouse tools for scalable data management in 2024. Learn how to choose the right platform for analytics, performance, and cost-efficiency.

Confused between a data mart and a data warehouse? Learn the key differences, use cases, and how to choose the right data architecture for your business. Explore best practices, real-world examples, and expert insights from Enqurious.

Discover the top 10 predictive analytics tools to know in 2025—from SAS and Google Vertex AI to RapidMiner and H2O.ai. Learn why predictive analytics is essential for modern businesses and how to choose the right tool for your data strategy.

Explore the key differences between descriptive and predictive analytics, and learn how both can drive smarter decision-making. Discover how these analytics complement each other to enhance business strategies and improve outcomes in 2025 and beyond.

Explore the key differences between predictive and prescriptive analytics, and learn how both can drive smarter decisions, enhance agility, and improve business outcomes. Discover real-world applications and why mastering both analytics approaches is essential for success in 2025 and beyond.

Compare PostgreSQL vs SQL Server in this comprehensive guide. Learn the key differences, strengths, and use cases to help you choose the right database for your business needs, from cost to performance and security.

Learn what Power BI is and how it works in this beginner's guide. Discover its key features, components, benefits, and real-world applications, and how it empowers businesses to make data-driven decisions.

Explore what a Business Intelligence Engineer does—from building data pipelines to crafting dashboards. Learn key responsibilities, tools, and why this role is vital in a data-driven organization.

Discover why data lineage is essential in today’s complex data ecosystems. Learn how it boosts trust, compliance, and decision-making — and how Enqurious helps you trace, govern, and optimize your data journeys.

Learn what a data mart is, its types, and key benefits. Discover how data marts empower departments with faster, targeted data access for improved decision-making, and how they differ from data warehouses and data lakes.

Learn how to bridge the digital skills gap with effective upskilling strategies. Discover how to foster a culture of continuous learning, personalize training with AI, and focus on future-ready skills.

Discover 5 key strategies to overcome upskilling and reskilling challenges in the age of AI. Learn how to build a future-ready workforce with personalized learning, cross-functional collaboration, and real-world application.

Explore the key differences between LXP and LMS platforms and learn which is best for your business in 2025. Discover how AI-driven learning systems can boost employee engagement and upskill your workforce for the future.

Discover 6 powerful ways to upskill employees and future-proof your workforce in the age of AI and data. Learn how leading organizations are adapting learning strategies to stay ahead.

Master data strategy: Understand data mart vs data warehouse key differences, benefits, and use cases in business intelligence. Enqurious boosts your Data+AI team's potential with data-driven upskilling.

Learn what Azure Data Factory (ADF) is, how it works, and why it’s essential for modern data integration, AI, and analytics. This complete guide covers ADF’s features, real-world use cases, and how it empowers businesses to streamline data pipelines. Start your journey with Azure Data Factory today!

Discover the key differences between SQL and MySQL in this comprehensive guide. Learn about their purpose, usage, compatibility, and how they work together to manage data. Start your journey with SQL and MySQL today with expert-led guidance from Enqurious!

Learn Power BI from scratch in 2025 with this step-by-step guide. Explore resources, tips, and common mistakes to avoid as you master data visualization, DAX, and dashboard creation. Start your learning journey today with Enqurious and gain hands-on training from experts!

AI tools like ChatGPT are transforming clinical data management by automating data entry, enabling natural language queries, detecting errors, and simplifying regulatory compliance. Learn how AI is enhancing efficiency, accuracy, and security in healthcare data handling.

Big Data refers to large, complex data sets generated at high speed from various sources. It plays a crucial role in business, healthcare, finance, education, and more, enabling better decision-making, predictive analytics, and innovation.

Explore the difference between reskilling and upskilling and why it matters for career growth and organizational success. Learn how reskilling helps workers pivot to new roles and how upskilling enhances current skills to stay competitive in today's fast-changing job market.

Discover the power of prompt engineering and how it enhances AI interactions. Learn the key principles, real-world use cases, and best practices for crafting effective prompts to get accurate, creative, and tailored results from AI tools like ChatGPT, Google Gemini, and Claude.

Explore the 6 core adult learning principles and how they can transform your training programs. Learn how to apply these principles for better engagement, retention, and real-world application, ensuring meaningful learning experiences for adult learners.

Discover the 9 key components of an effective learning experience and how they drive better engagement, retention, and real-world application. Learn how organizations can implement these elements to create impactful learning journeys.

Boost your Business Intelligence skills in 2025 with 25 hands-on exercises that cover data analysis, visualization, SQL, and more. Perfect for professionals looking to sharpen their BI expertise and stay ahead in the competitive job market.

Learn what a Logical Data Model (LDM) is, its key components, and why it’s essential for effective database design. Explore how an LDM helps businesses align data needs with IT implementation, reducing errors and improving scalability.

Discover the power of a Canonical Data Model (CDM) for businesses facing complex data integration challenges. Learn how CDM simplifies communication between systems, improves data consistency, reduces development costs, and enhances scalability for better decision-making.

Learn about Learning Management Systems (LMS), their key benefits, and popular examples like Moodle, Google Classroom, and Enqurious. Discover how LMS platforms are revolutionizing education and training for businesses and schools.

Discover the 10 essential benefits of Engineering Data Management (EDM) and how it helps businesses streamline workflows, improve collaboration, ensure security, and make smarter decisions with technical data.

Explore how vibe coding is transforming programming by blending creativity, collaboration, and technology to create a more enjoyable, productive, and human-centered coding experience.

Learn how Azure Databricks empowers data engineers to build optimized, scalable, and reliable data pipelines with features like Delta Lake, auto-scaling, automation, and seamless collaboration.

Discover how AI is transforming workplace learning and development by personalizing training, delivering real-time feedback, and aligning learning with business goals to drive workforce excellence and growth.

Explore the top 10 data science trends to watch out for in 2025. From generative AI to automated machine learning, discover how these advancements are shaping the future of data science and transforming industries worldwide.

Discover why a Capstone Project is essential in 2025. Explore how it bridges the gap between theory and practice, enhances problem-solving skills, provides industry experience, and prepares students for real-world challenges. Learn how capstone projects are shaping future careers.

Discover the key differences between data scientists and data engineers, their roles, responsibilities, and tools. Learn how Enqurious helps you build skills in both fields with hands-on, industry-relevant learning.

Discover the 9 essential steps to effective engineering data management. Learn how to streamline workflows, improve collaboration, and ensure data integrity across engineering teams.

Azure Databricks is a cloud-based data analytics platform that combines the power of Apache Spark with the scalability, security, and ease of use offered by Microsoft Azure. It provides a unified workspace where data engineers, data scientists, analysts, and business users can collaborate.

In today's data-driven world, knowing how to make sense of information is a crucial skill. We’re surrounded by test scores, app usage stats, survey responses, and sales figures — and all this raw data on its own isn’t helpful.

In this blog, we will discuss some of the fundamental differences between AI inference vs. training—one that is, by design, artificially intelligent.

This guide provides a clear, actionable roadmap to help you avoid common pitfalls and successfully earn your SnowPro Core Certification, whether you’re making a career pivot or leveling up in your current role.

"Ever had one of those days when you’re standing in line at a store, waiting for a sales assistant to help you find a product?" In this blog we will get to know about -What is RAG, different types of RAG Architectures and pros and cons for each RAG.

Discover how Databricks and Snowflake together empower businesses by uniting big data, AI, and analytics excellence

How do major retailers like Walmart handle thousands of customer queries in real time without breaking a sweat? From answering questions instantly to providing personalized shopping recommendations, conversational AI reshapes how retailers interact with their customers.

In today’s rapidly evolving job market, the value of evidence-based skills has never been more critical. As industries shift and technology transforms how we work, the need for tangible proof of competencies has become paramount.

In today’s rapidly evolving technological landscape, one skill stands out above all others: learnability. Learnability, often described as the ability to continuously acquire new skills and adapt to change, is no longer just an advantage but a necessity.

To build a future-ready workforce, companies need to rethink talent strategies. Start by developing a data-driven talent system to align key roles with best-fit talent. Invest in AI training now to stay ahead, and shift hiring practices to focus on skills, not just job titles.

At Enqurious, we understand the importance of empowering workforces with the right skills to navigate emerging challenges. Enqurious works as a strategic partner to supplement and enhance L&D Teams.

Understanding how variables work together can supercharge your marketing strategy.

Marketing Effectiveness: Strategies, Channels, and ROI Maximization

The transformative journey of the energy sector: from outdated practices to a data-driven revolution.

Enhancing Readability for Effective Learning and Development

Thoughtfully crafted instruction design with drops of ambiguity and room for creative thinking makes the learning experience more enjoyable and “real world”.

Even after putting the best of the content, infrastructure and people, the gap between the intention of organizations to foster a culture of learning and the actual implementation and adoption of learning initiatives by employees keeps on widening.

Understanding why it is so important to nurture self driven learners in a fast paced technology world

Leveraging data to design better and efficient L&D strategy for organization success