
How to Identify Skill Gaps in Your Data Team
Ready to transform your data strategy with cutting-edge solutions?
"The goal isn't to test your team. It's to create conditions where skill reveals itself naturally, where gaps become visible before they become incidents."
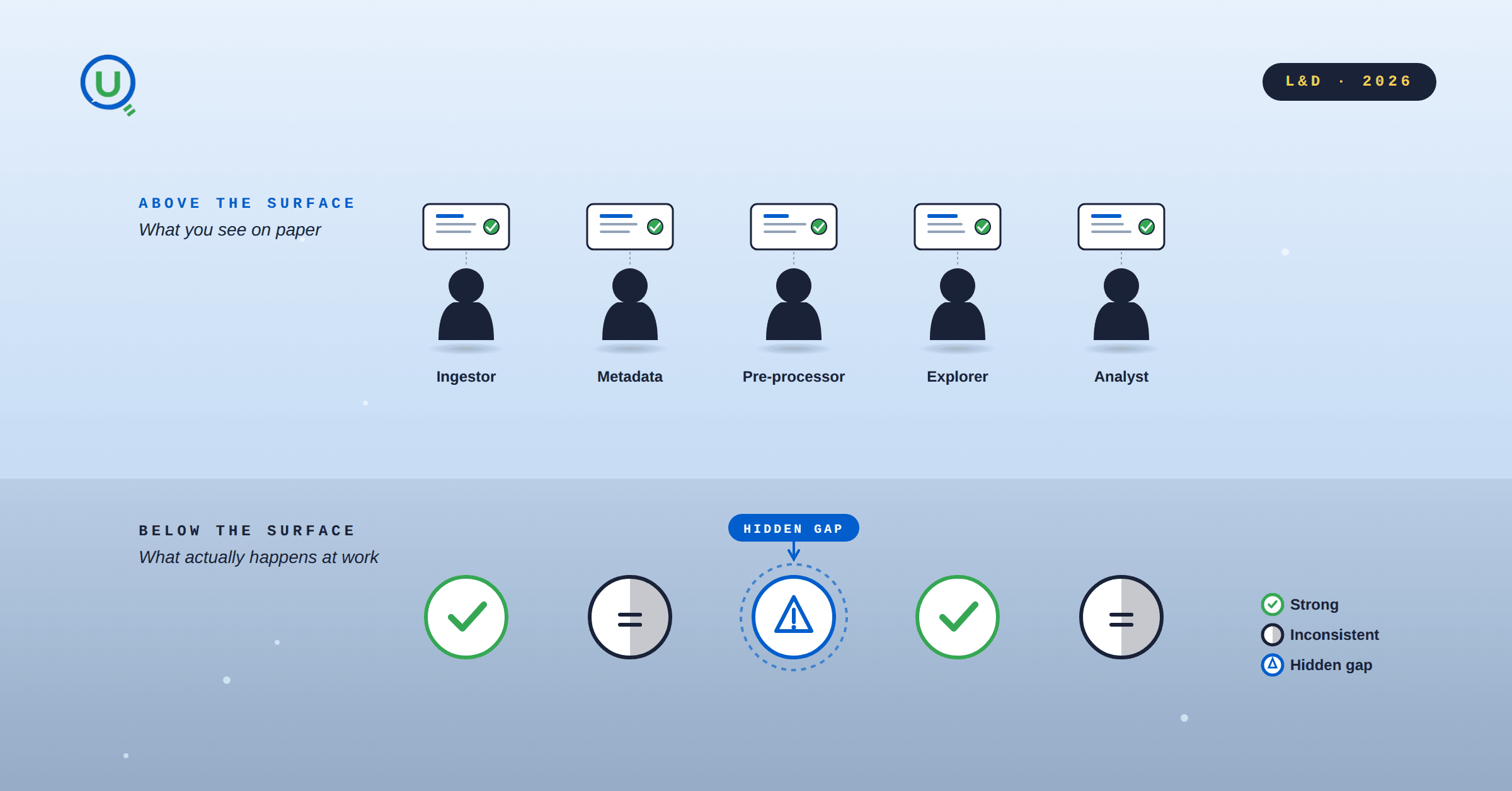
You have a data team of seven people. Each one has a title on a slide deck, a role in a RACI chart, and a reasonable salary. On paper, the team is complete. But somewhere between the raw data landing in your pipeline and the insight landing on the CEO's desk, things keep going wrong. Not catastrophically, just quietly.
Reports take too long. Errors slip through. No one quite owns the messy middle.
The usual instinct is to hire. Or to buy a tool. But more often than not, the problem isn't headcount. It is uneven competence hidden under consistent job titles. The question isn't "do we have enough people?" It is "do our people know what they think they know?"
The pd.read_csv Test
Here is a concrete example before we get to methodology. Your pre processing engineer is about to load a data file. The file has a .xlsx extension. It is an Excel file. They reach for pandas and type:
python
# This will fail, or silently misparse
df = pd.read_csv("sales_data.xlsx")This is not a typo. This is a knowledge gap.
pd.read_csv reads comma separated text files. An .xlsx file is a binary Office Open XML format. Calling read_csv on it either throws a parser error or, worse, returns garbled data that looks fine at first glance.
The correct call:
python
# Correct
df = pd.read_excel("sales_data.xlsx")
# Or with an explicit engine:
df = pd.read_excel("sales_data.xlsx", engine="openpyxl")One small mistake. But it reveals something important: this person has been using pandas without truly understanding it. Scale that across a team of seven and you start to see why things quietly go wrong.
Stop Assessing Skills. Start Observing Them.
The traditional approach to skill gap analysis is the survey. You send around a spreadsheet, ask people to rate themselves from 1 to 5 on SQL, Python, statistics, and communication, and colour code the results. This produces a beautiful heat map and almost no useful information.
People are bad at accurately self assessing technical skills. Those who know the least tend to overestimate (the Dunning Kruger effect, alive and well in data teams). Those who are strongest often underestimate, because they see the full scope of what they don't know.
The survey tells you about confidence, not competence.
A better method is to engineer observable moments. Here are three that work in practice.
Method 1: The Code Review Round Table
Take a real piece of working code from your pipeline, something your team already uses, and run a structured review session. For every block of code, ask three questions:
# | Question | What it filters |
|---|---|---|
1 | What does this code actually do? | Basic comprehension |
2 | Why was it written this way? | Contextual judgment |
3 | Is there a better alternative, and what are the trade-offs? | Depth of reasoning |
You're not looking for perfect answers. You're watching for the moments people go quiet, give vague non answers, or confidently state something incorrect. Those moments are your data points.
Rotate the code examples across domains: one from SQL, one from Python, one from a pipeline config. You'll quickly see:
Who is broad vs. who is narrow
Who reasons vs. who remembers
Who can articulate trade-offs vs. who can only describe behaviour
Method 2: The Role Swap Walkthrough
Ask your ingestion engineer to walk you through what the metadata reviewer does, and vice versa. Not to do the job. Just to explain it.
The goal is to surface assumed knowledge and hidden dependencies.
In healthy data teams, people have enough overlap to cover for each other and catch errors across handoffs. In skill gap heavy teams, each person is a silo who trusts the previous step without questioning it.
The pre processor who loads an .xlsx with read_csv and gets a garbled dataframe might not even flag it. Because they don't have enough domain knowledge to recognise that the shape of the data looks wrong.
What to listen for during walkthroughs:
Can they name the tools their colleague uses, and why?
Do they understand what a bad handoff from the previous step looks like?
Can they describe what "done correctly" means for a role that isn't theirs?
Method 3: The Break and Fix Simulation
Introduce a subtle, intentional bug into a sandboxed version of a real dataset or pipeline. Something realistic that a professional should catch. Then ask team members to process it as normal and report back.
You're not setting a trap. You're seeing how far signals travel before someone raises a flag.
Watch for these specific signals:
Does the person validate output shape before proceeding, or do they pass it downstream without checking?
When something looks off, do they investigate, or do they shrug and ship it?
Can they articulate why something is wrong, not just that it is wrong?
Do they know what a healthy version of this data should look like?
The break and fix simulation reveals data literacy at the most practical level. It is the difference between someone who runs a function because it is in their playbook, and someone who understands what the function is doing to the data.
What You're Actually Looking For
Across all three methods, you're building a picture of two distinct things that get conflated all the time:
Procedural Knowledge (knowing the steps) | Conceptual Understanding (knowing why the steps work) |
|---|---|
Runs | Knows what CSV vs. |
Writes a JOIN query | Understands index performance impact |
Fills a pipeline config | Knows what happens when it breaks |
Passes QA checklist | Can reason about edge cases not listed |
Most onboarding and most self assessments measure the first column. Skill gaps almost always live in the second.
After the Assessment: Don't Build a Training Plan
The instinct after mapping skill gaps is to assign courses. "Person X has a gap in file formats. Send them a Pandas tutorial." Resist this.
Formal training solves for surface knowledge, not for the judgment that comes from working through real problems with better informed colleagues.
The most effective gap closure strategies are structural:
Pair, don't train. Put the person with the gap alongside the person without it on a real project, not a learning exercise.
Make code review a norm, not a corrective action reserved for when things break.
Run post incident reviews that ask "what did we not know?" instead of "who made the mistake?"
Build shared language. Terminology alignment sessions prevent the class of error where two people think they're talking about the same thing and aren't.
The data team that reads .xlsx files correctly isn't better because they attended a training. They're better because they work in an environment where someone would catch that and explain it.
The Real Problem
Skill gaps, ultimately, are as much a culture problem as a knowledge problem.
The gap isn't just that someone doesn't know. It is that no one noticed they didn't know, until it was too late.
The pd.read_csv scenario is real. Variations of it appear weekly in data teams everywhere. If you've seen it in yours, you already know where to start.
If you found this useful, the next step is to map your own team against the observable signal matrix above. Not by asking them to self assess. By sitting in on one code review session and watching who goes quiet.
Ready to Experience the Future of Data?
You Might Also Like
Spark optimization isn't always complex; some tweaks have a huge impact. Inferring schemas forces Spark to scan your data twice, slowing ingestion and inflating cost. Explicit schemas avoid the extra pass and make pipelines faster and cheaper.

A practical walkthrough of how I reduced heavy batch workloads using Change Data Feed (CDF) in Databricks. This blog shows how CDF helps process only updated records, cutting compute costs and boosting pipeline efficiency.

Why DELETE isn’t enough under GDPR, and how Time Travel can make sensitive data reappear unless VACUUM is used correctly.

A complete guide to building a future-ready L&D team in 2025. Explore the roles, skills, structure, and AI-driven strategies that drive real business impact.

Learn how to bridge the digital skills gap with effective upskilling strategies. Discover how to foster a culture of continuous learning, personalize training with AI, and focus on future-ready skills.

Discover 5 key strategies to overcome upskilling and reskilling challenges in the age of AI. Learn how to build a future-ready workforce with personalized learning, cross-functional collaboration, and real-world application.

Explore the key differences between LXP and LMS platforms and learn which is best for your business in 2025. Discover how AI-driven learning systems can boost employee engagement and upskill your workforce for the future.

Discover 6 powerful ways to upskill employees and future-proof your workforce in the age of AI and data. Learn how leading organizations are adapting learning strategies to stay ahead.

Explore the difference between reskilling and upskilling and why it matters for career growth and organizational success. Learn how reskilling helps workers pivot to new roles and how upskilling enhances current skills to stay competitive in today's fast-changing job market.

Explore the 6 core adult learning principles and how they can transform your training programs. Learn how to apply these principles for better engagement, retention, and real-world application, ensuring meaningful learning experiences for adult learners.

Discover the 9 key components of an effective learning experience and how they drive better engagement, retention, and real-world application. Learn how organizations can implement these elements to create impactful learning journeys.

Boost your Business Intelligence skills in 2025 with 25 hands-on exercises that cover data analysis, visualization, SQL, and more. Perfect for professionals looking to sharpen their BI expertise and stay ahead in the competitive job market.

Learn about Learning Management Systems (LMS), their key benefits, and popular examples like Moodle, Google Classroom, and Enqurious. Discover how LMS platforms are revolutionizing education and training for businesses and schools.

Discover how AI is transforming workplace learning and development by personalizing training, delivering real-time feedback, and aligning learning with business goals to drive workforce excellence and growth.

Discover why a Capstone Project is essential in 2025. Explore how it bridges the gap between theory and practice, enhances problem-solving skills, provides industry experience, and prepares students for real-world challenges. Learn how capstone projects are shaping future careers.

In today’s rapidly evolving job market, the value of evidence-based skills has never been more critical. As industries shift and technology transforms how we work, the need for tangible proof of competencies has become paramount.

In today’s rapidly evolving technological landscape, one skill stands out above all others: learnability. Learnability, often described as the ability to continuously acquire new skills and adapt to change, is no longer just an advantage but a necessity.

To build a future-ready workforce, companies need to rethink talent strategies. Start by developing a data-driven talent system to align key roles with best-fit talent. Invest in AI training now to stay ahead, and shift hiring practices to focus on skills, not just job titles.

At Enqurious, we understand the importance of empowering workforces with the right skills to navigate emerging challenges. Enqurious works as a strategic partner to supplement and enhance L&D Teams.

Understanding how variables work together can supercharge your marketing strategy.

Marketing Effectiveness: Strategies, Channels, and ROI Maximization

The transformative journey of the energy sector: from outdated practices to a data-driven revolution.

Enhancing Readability for Effective Learning and Development

This guide helps to understand what elements come together to make or break a visual

Thoughtfully crafted instruction design with drops of ambiguity and room for creative thinking makes the learning experience more enjoyable and “real world”.

Even after putting the best of the content, infrastructure and people, the gap between the intention of organizations to foster a culture of learning and the actual implementation and adoption of learning initiatives by employees keeps on widening.

Understanding why it is so important to nurture self driven learners in a fast paced technology world

Leveraging data to design better and efficient L&D strategy for organization success