
Data Lakehouse Demystified: Unlocking Databricks’ Hidden Powers in 2025

Ready to transform your data strategy with cutting-edge solutions?
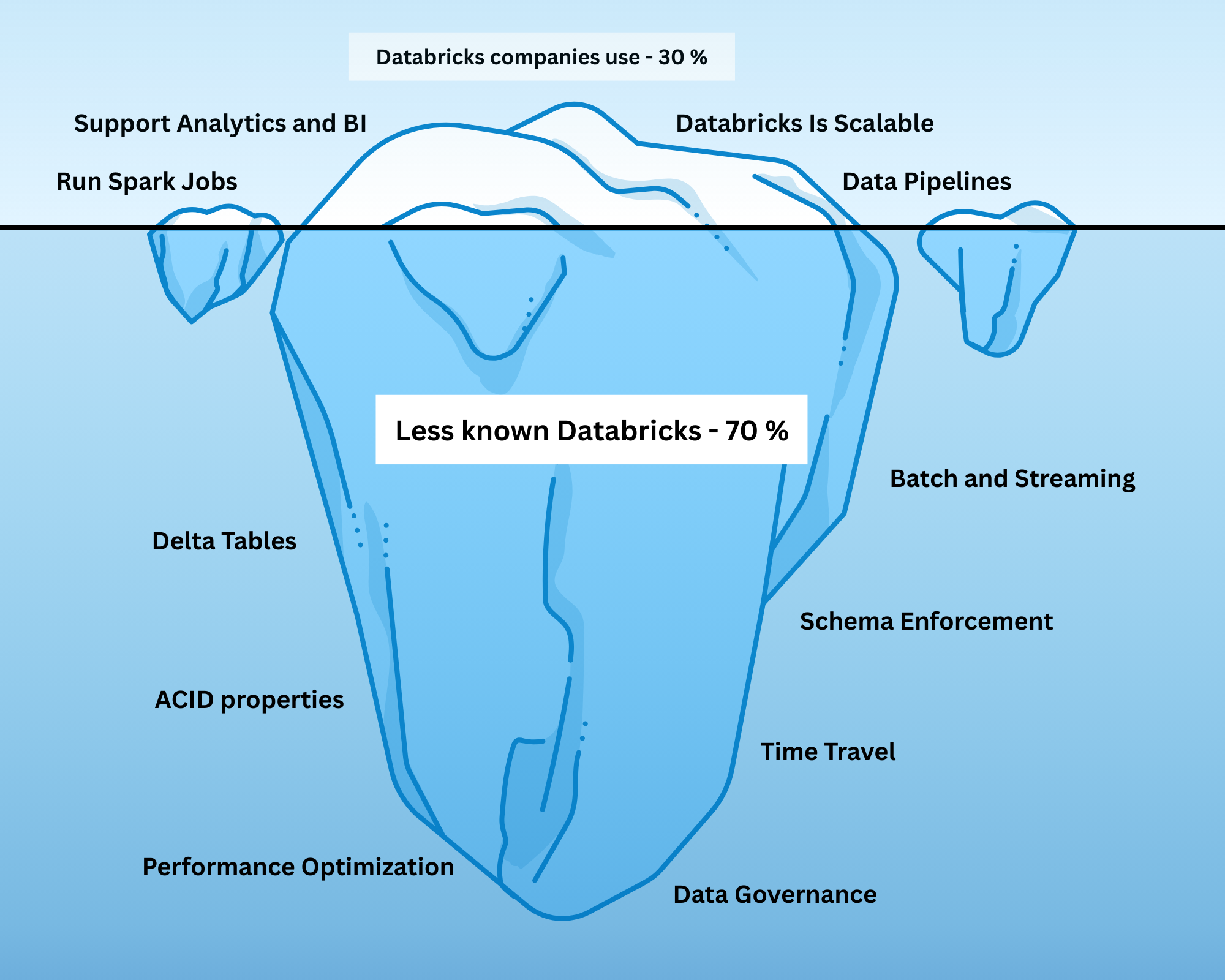
In today’s data-driven world, organizations are integrating Databricks to manage large-scale data pipelines, perform analytics, and deploy machine learning workflows. Databricks promises a unified platform, simplified data operations, and powerful scalability for diverse workloads.
However, many teams only scratch the surface. They create Spark jobs, spin up Delta tables, and build pipelines - but the true power of Databricks lies in its Lakehouse architecture. Without fully understanding this, even sophisticated setups can result in inefficiencies, unreliable data, and frustrated data teams.
Did you know that Databricks allows you to:
- Travel back in time using historical table versions?
- Enforce schemas so your data behaves predictably?
- Perform updates, deletes, and incremental processing safely?
These are not optional add-ons - they are core features of the Lakehouse. The Lakehouse combines the strengths of data lakes and data warehouses into a single platform, enabling engineers to manage, govern, and analyze data efficiently.
Challenges in Traditional Data Architecture: Why Teams Needed a Better Approach
Before the Lakehouse, data engineers were stuck navigating two imperfect systems: traditional warehouses and data lakes.
Each came with unique advantages, but also major limitations.
Limitations of Data Warehouses
Data warehouses, such as Snowflake, BigQuery, and Redshift, are optimized for structured data, analytics, and reporting. They provide:
- Strong governance and consistency
- Optimized query performance for analytics
- Reliable and structured storage
However, warehouses struggle with:
- Semi-structured or unstructured data, such as logs or JSON files
- Streaming and near-real-time ingestion
- Cost and scalability for massive datasets
- Supporting machine learning workflows without duplicating data
These limitations made warehouses expensive and rigid, especially for modern, diverse data workloads.

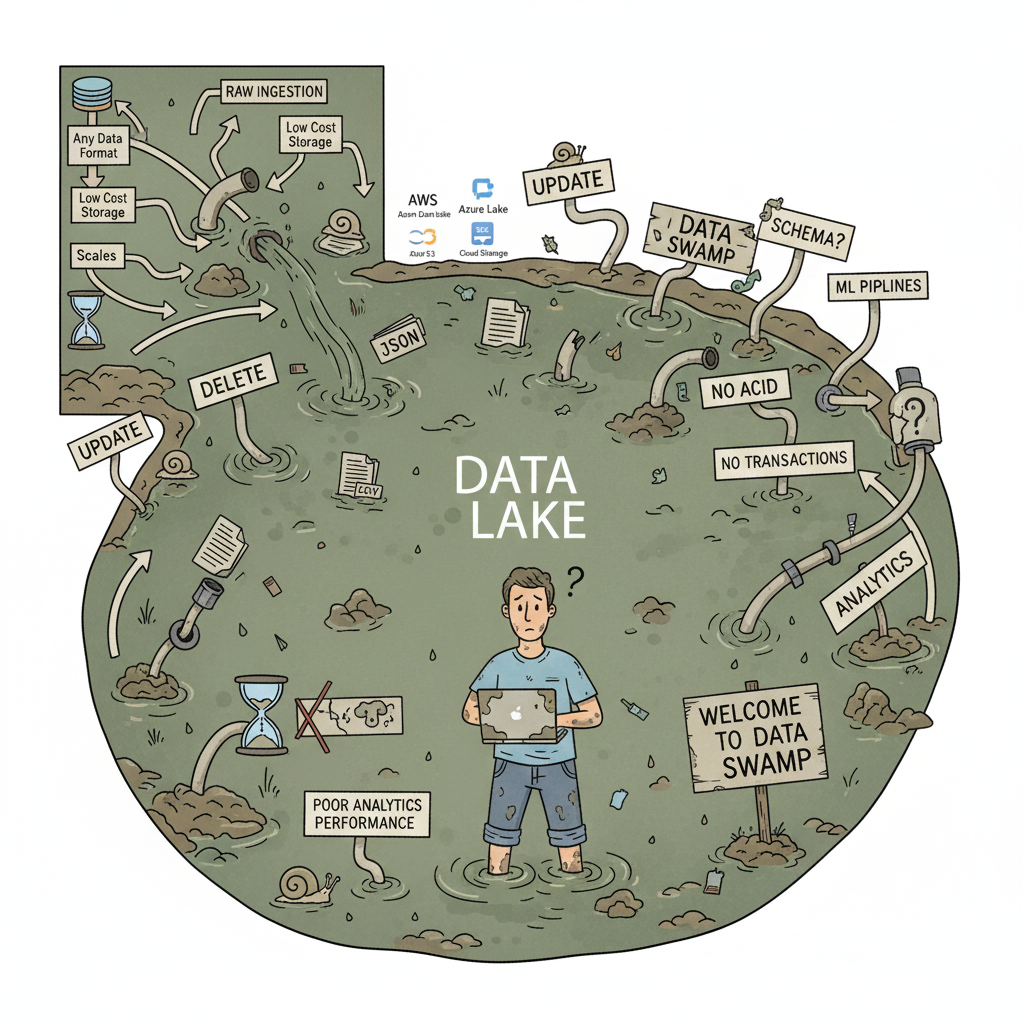
Limitations of Data Lakes
Data lakes, such as AWS S3, Azure Data Lake Storage, or Google Cloud Storage, were designed to store massive amounts of raw data at low cost. They allow organizations to:
- Ingest any data format: structured, semi-structured, or unstructured
- Scale storage cheaply to petabytes of data
- Support exploratory data analysis and advanced analytics
However, lakes have critical shortcomings:
- Lack of transactional guarantees—updates and deletes are risky
- Weak schema enforcement, which can lead to inconsistent or corrupt data
- Query performance often poor for analytics
- Without proper governance, lakes can quickly become “data swamps”
This often forced organizations to maintain multiple systems: OLTP databases for apps, lakes for raw storage, warehouses for analytics, and complex pipelines to connect them. The result: fragmentation, inefficiency, and higher operational risk.
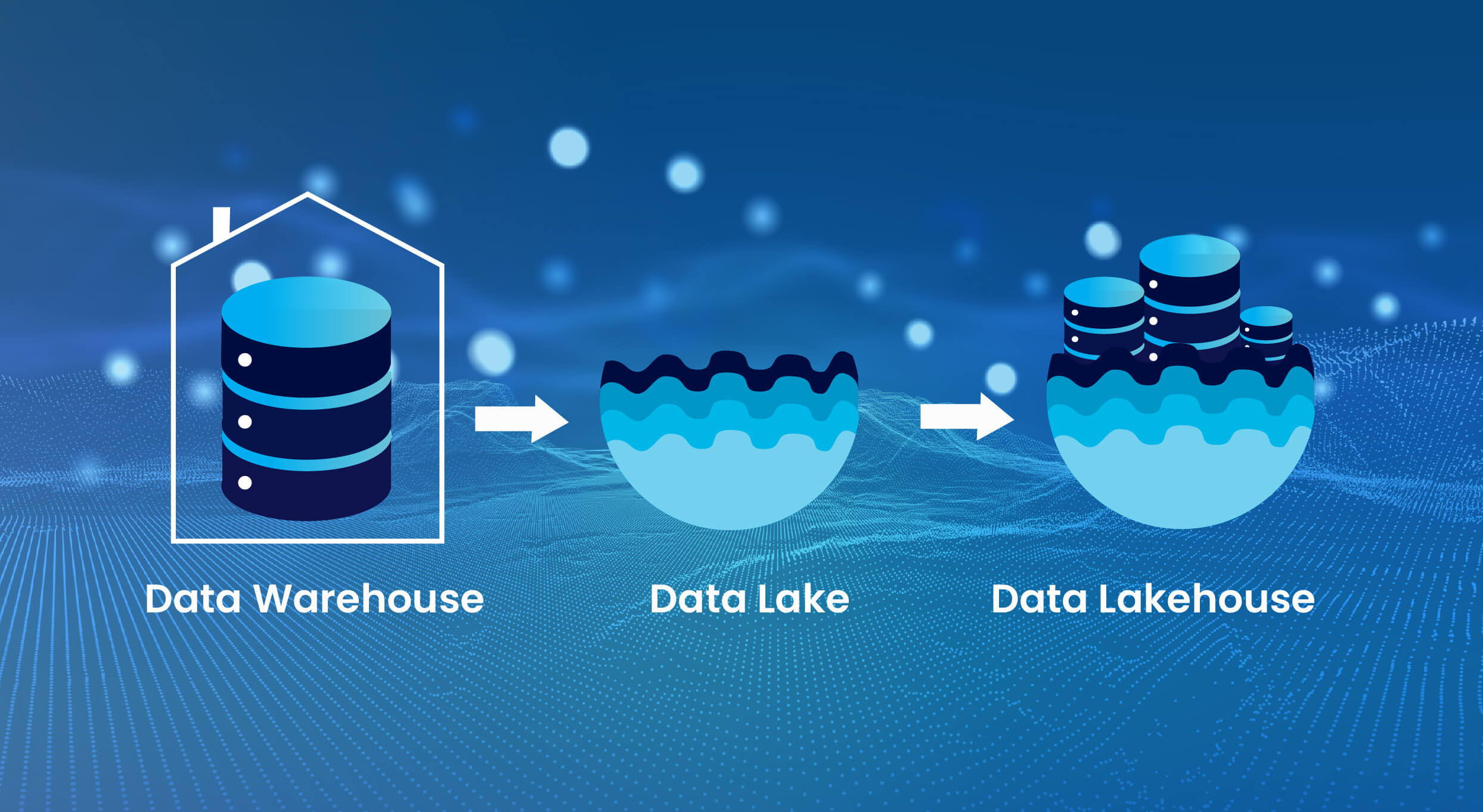
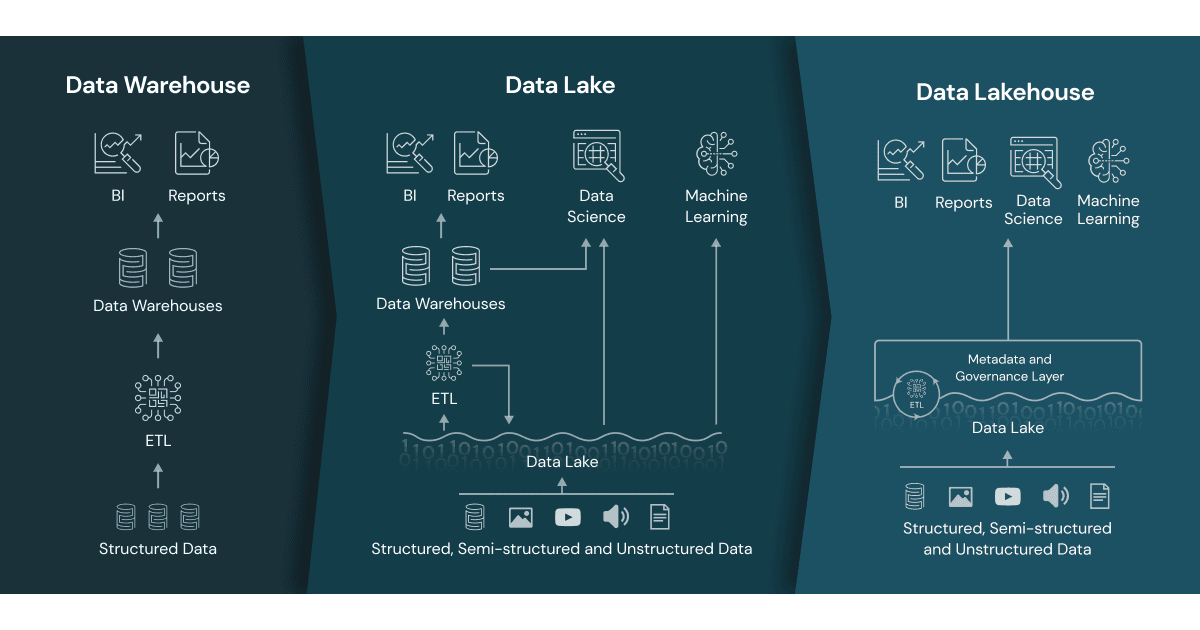
Definition of a Data Lakehouse: A Unified, Storage-Optimized Architecture
A Data Lakehouse is a storage-optimized layer built on top of cloud object storage. Unlike traditional warehouses and lakes (which are data stores), the Lakehouse is designed to store, process, and serve data reliably across all stages of the data lifecycle.
The Lakehouse combines:
- The flexibility of data lakes, allowing raw and semi-structured data ingestion
- The reliability and structure of data warehouses, supporting analytics and business reporting
This architecture enables organizations to reduce data duplication, simplify pipelines, and manage diverse workloads—**all in one platform**.
Delta Tables: The Core Component of a Lakehouse
At the heart of the Lakehouse are Delta tables. They are what make the architecture transactional, reliable, and analytics-ready. Delta tables store data in two complementary formats:
1. Delta Format – Contains metadata, versioning, and transaction logs
2. Parquet Format – Columnar storage optimized for analytics and query performance
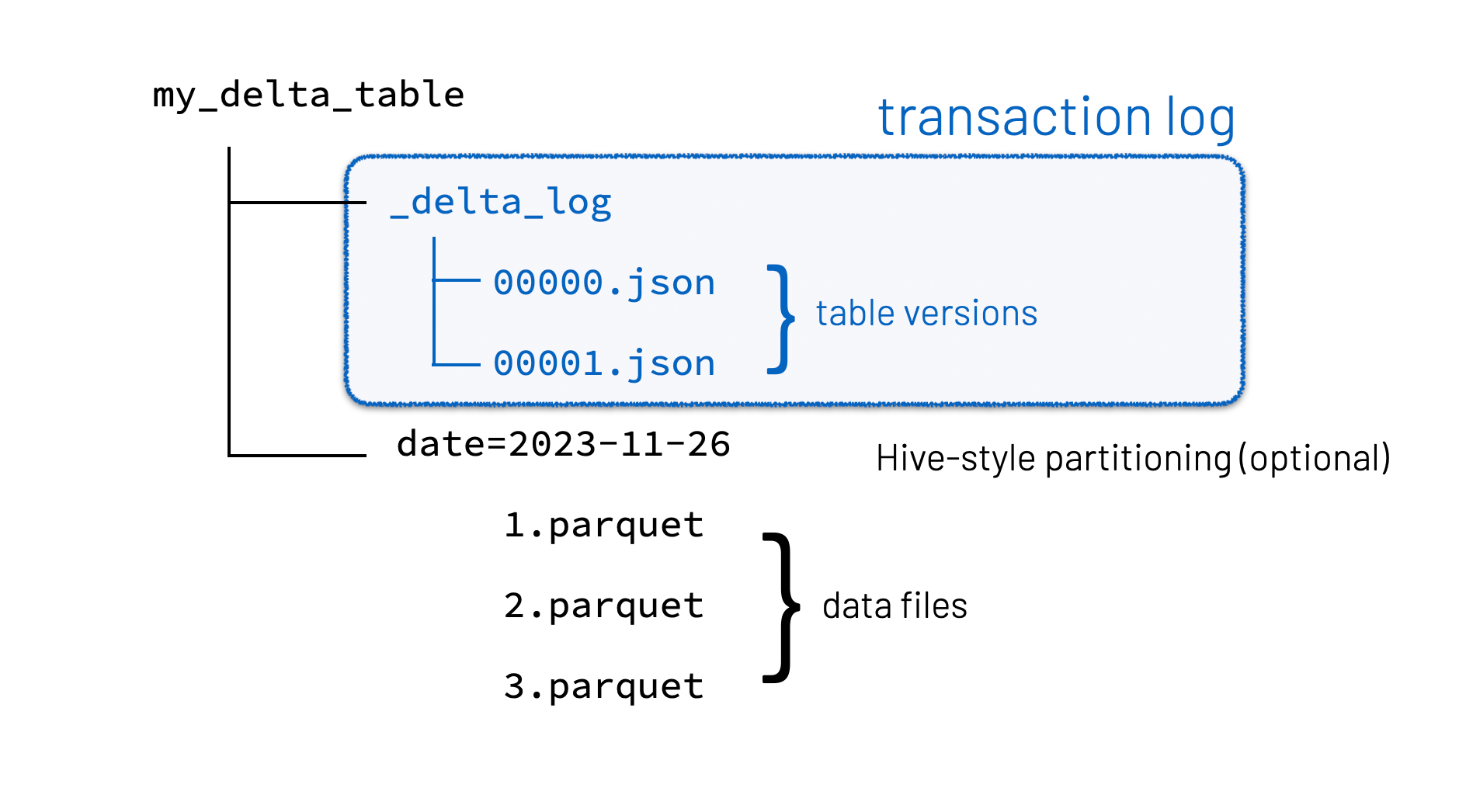
This dual-format design enables several critical capabilities:
- ACID Transactions: Ensure consistent reads and writes, allowing multiple users to interact with the same tables without conflicts. Updates, deletes, and inserts become reliable and traceable.
- Time Travel: Query historical versions of your data to reproduce reports, debug pipelines, or roll back errors.
- Schema Enforcement and Evolution: Prevent corrupt or incompatible data from entering your tables, while allowing safe evolution over time.
> Think of Delta tables as a well-trained data assistant: it stores everything efficiently, keeps your data consistent, and lets you reverse mistakes easily.
Key Features of the Data Lakehouse: Why It Matters for Data Engineers
The Lakehouse is not just a storage solution—it’s a complete data management framework that empowers engineers to deliver reliable, scalable, and high-quality data. Here are the most important capabilities:
1. ACID Transactions
ACID transactions ensure that all changes to data are atomic, consistent, isolated, and durable. This allows multiple users or pipelines to interact with data safely and prevents partial updates or corrupt datasets.

2. Time Travel and Versioning
Every change in a Delta table is logged as a version. This allows teams to:
- Access previous snapshots of data
- Debug pipelines efficiently
- Recreate past reports exactly as they were
Time travel reduces operational risk and improves trust in the data.
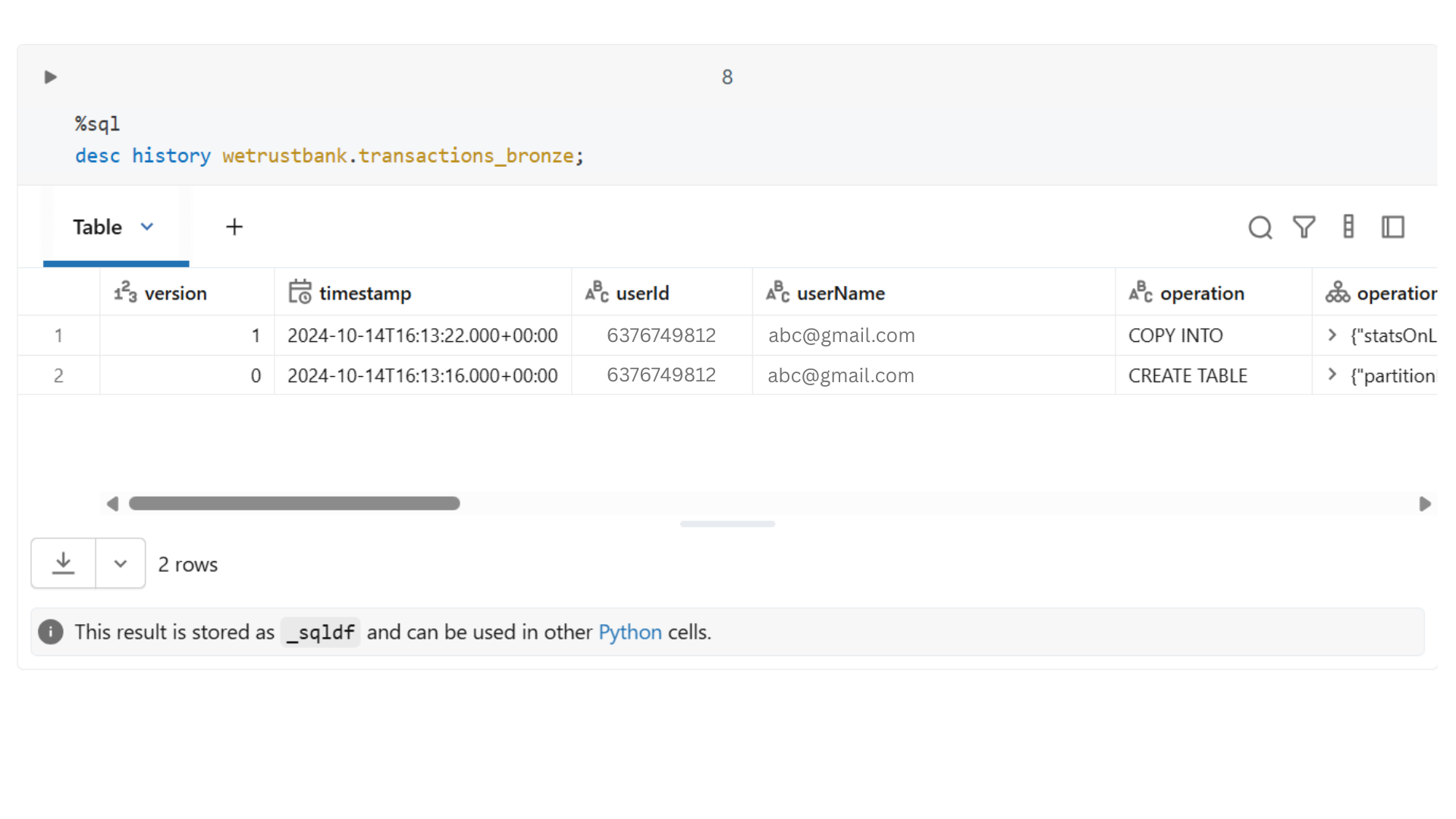
3. Schema Enforcement and Evolution
Data consistency is critical. Delta tables allow:
- Automatic schema enforcement to block invalid or unexpected data
- Controlled schema evolution to safely accommodate new fields
- Reduction in downstream errors or pipeline failures
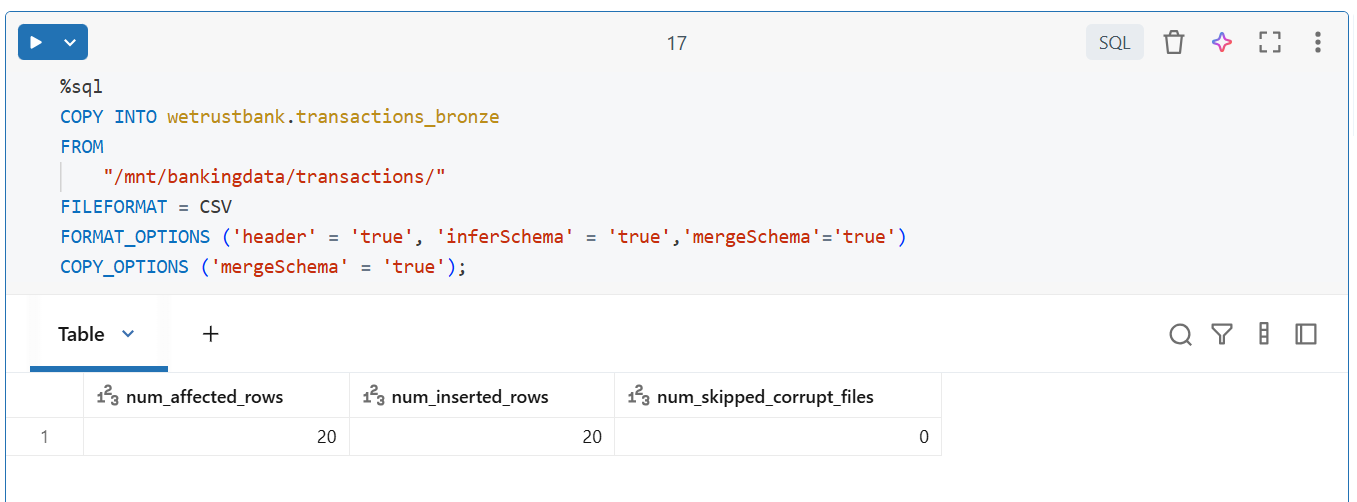
4. Unified Batch and Streaming Processing
The Lakehouse allows batch and streaming data to coexist in the same tables, ensuring:
- Consistent data across pipelines
- Simplified architecture without multiple systems
- Reliable real-time analytics
5. Storage Optimization and Query Performance
Delta tables combine transaction logs and Parquet storage, offering:
- Fast queries with columnar data format
- Reduced storage footprint through efficient file compaction
- Automatic handling of small files in streaming or batch ingestion
How to Leverage Delta Tables in Your Data Engineering Work
Delta tables are central to maximizing the value of the Lakehouse. Here’s how engineers can use them effectively:
1. Simplifying ETL Pipelines
Delta tables allow engineers to:
- Read raw data, apply transformations, and write directly into Delta tables
- Handle incremental data loads efficiently
- Ensure idempotent operations, preventing duplicates or errors
> Example: Using the MERGE INTO command, new sales transactions can be automatically merged into analytics tables, reducing manual coding.
2. Maintaining Data Quality
Delta tables enforce schema rules:
- Invalid data is blocked automatically
- Safe schema evolution allows addition of new fields without breaking pipelines
> Example: Adding a customer_segment column in a sales table doesn’t break dashboards or downstream analytics.
3. Enabling Time Travel
Historical snapshots are automatically logged:
- Query older versions of data
- Recover deleted or corrupted records
- Reproduce previous reports exactly
> Example: Debug a reporting error by querying last week’s table version instead of reprocessing raw data.
4. Supporting Concurrent Workloads
ACID transactions allow:
- Multiple pipelines and users to interact with the same table simultaneously
- Real-time dashboards to run alongside batch processing
> Example: Marketing dashboards can update in real-time while finance reconciles transactions.
5. Optimizing Storage and Query Performance
Delta tables optimize performance with:
- Columnar storage in Parquet
- File compaction for streaming or batch ingestion
- Partitioning for faster filtering
> Example: Streaming web logs append to Delta tables without generating millions of small files, keeping queries fast.
6. Simplifying Data Governance and Compliance
Delta tables enhance governance:
- Maintain historical versions for audits
- Track row-level changes for accountability
- Ensure downstream consumers access validated, clean data
> Example: GDPR compliance is easier when you can trace back to the exact version used for a report.
Practical Tips for Data Engineers
- Partition tables based on frequently filtered columns (e.g., date)
- Use Z-order clustering for multi-column queries
- Regularly vacuum old versions to manage storage costs
- Prefer MERGE INTO over manual joins for upserts
By following these best practices, Delta tables become a powerful tool for building scalable, reliable pipelines.
Common Pitfalls in Lakehouse Implementation
Even experienced Databricks users can make mistakes:
- Treating Delta tables like regular files without transactions
- Mixing raw and processed data in the same tables
- Building dashboards directly on uncurated raw data
- Ignoring time travel or rollback capabilities
- Skipping schema enforcement and pipeline design principles
Proper understanding and disciplined implementation ensures reliable and trustworthy pipelines.
Benefits of the Data Lakehouse for Data Engineers
For data engineers, the Lakehouse provides:
1. Simplified Architecture – Reduces fragmented systems and redundant pipelines
2. Enforced Data Quality – Ensures consistency, validation, and trustworthiness
3. Integrated Analytics and ML – Single platform for batch, streaming, and ML workloads
4. Operational Reliability – Prevents pipeline failures with ACID transactions and versioning
5. Improved Productivity – Engineers focus on value-added work rather than firefighting
> The Lakehouse shifts the engineer’s role from moving data to maturing data for reliability and scalability.
Real-World Example: Leveraging the Lakehouse for Business Insights
Consider a retail company ingesting millions of transactions daily. Without the Lakehouse:
- Raw data lands in a data lake, uncurated
- Analytics queries on raw data are inconsistent
- Multiple pipelines move data between lakes, warehouses, and reporting systems
With a Lakehouse on Databricks:
- Delta tables handle transactions reliably
- Historical snapshots enable audits and debugging
- Clean, trusted data is available for dashboards and ML models
- Single architecture supports batch and streaming workloads
Result: Faster insights, reduced operational overhead, and trustworthy pipelines.
Conclusion: Databricks Is the Tool; Lakehouse Is the Mindset
Using Databricks without understanding the Lakehouse is like driving a Ferrari in first gear—you have the potential, but you’re underutilizing it.
By mastering:
- Delta tables and ACID transactions
- Time travel and versioning
- Schema enforcement and unified batch/streaming processing
- Data curation and quality principles
…data engineers can design scalable, reliable, and trusted pipelines, unlocking the full potential of Databricks.
> The Lakehouse is not just a feature—it is the foundation of modern data engineering, enabling smarter, faster, and more reliable data operations.
Ready to Experience the Future of Data?
You Might Also Like
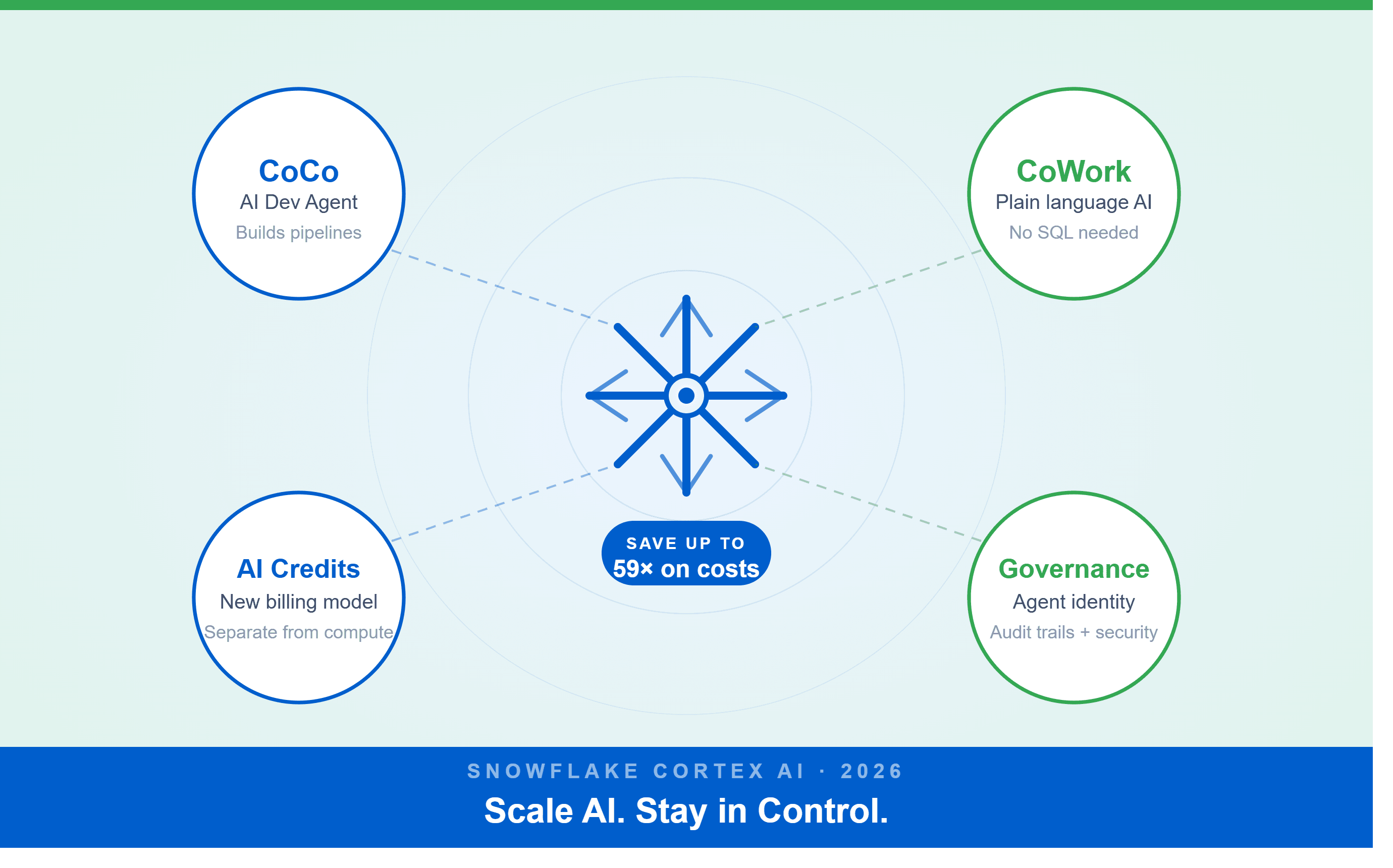
A Snowflake Summit 2026 benchmark revealed a 59x cost gap — open-source models at 440 credits vs. frontier models at 26,000 credits for identical workloads. Learn how CoCo, CoWork, AI Credits, and Cortex Training change enterprise AI strategy.
How a data engineering team replaced manual pipeline work with natural language prompts, using Claude Code and the Databricks AI Dev Kit.

Six errors, 6 hours of debugging, and the permission checklist that finally made Databricks Apps + Genie work. The full lessons-learned guide.

Your Claude Code session isn't lost. It's on disk, in a folder /resume isn't scanning. Here's how to find any session in 30 seconds, with the exact commands.

Scenario based learning replaces tutorials with realistic operational scenarios where engineers develop the hands on judgment classroom instruction cannot produce. How it works and why it matters.
The 2026 data engineering roadmap. SQL, Python, cloud, Airflow, dbt, streaming. What companies actually hire for and how to build a portfolio that gets shortlisted.
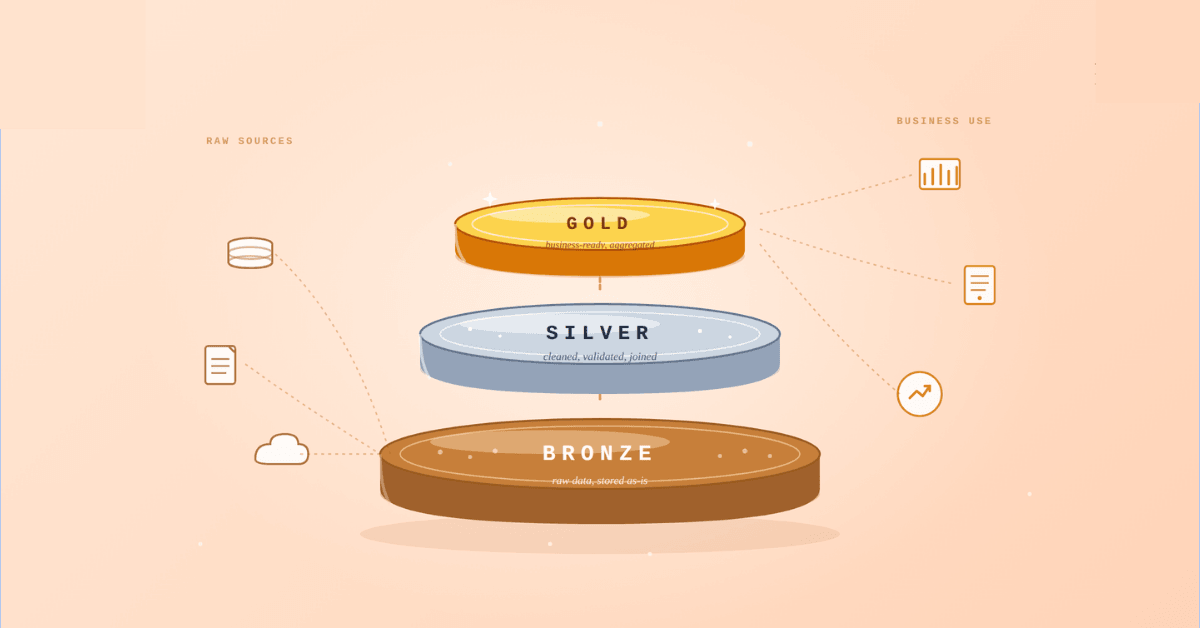
Medallion Architecture splits your data pipeline into Bronze, Silver, and Gold layers so a small business change never forces a full rebuild. Here's why it works.

I was working on a large content repository on Windows, and I needed to version some new work — campaign assets, workshop content, LinkedIn job descriptions, and some file deletions. Simple enough, right? What followed was a two-day journey through some of Git's more obscure corners.

A complete beginner’s guide to data quality, covering key challenges, real-world examples, and best practices for building trustworthy data.

Data doesn’t wait - and neither should your insights. This blog breaks down streaming vs batch processing and shows, step by step, how to process real-time data using Azure Databricks.

This blog talks about Databricks’ Unity Catalog upgrades -like Governed Tags, Automated Data Classification, and ABAC which make data governance smarter, faster, and more automated.

Tired of boring images? Meet the 'Jai & Veeru' of AI! See how combining Claude and Nano Banana Pro creates mind-blowing results for comics, diagrams, and more.
This blog walks you through how Databricks Connect completely transforms PySpark development workflow by letting us run Databricks-backed Spark code directly from your local IDE. From setup to debugging to best practices this Blog covers it all.
Master the bronze layer foundation of medallion architecture with COPY INTO - the command that handles incremental ingestion and schema evolution automatically. No more duplicate data, no more broken pipelines when new columns arrive. Your complete guide to production-ready raw data ingestion

This blog talks about the Power Law statistical distribution and how it explains content virality

An account of experience gained by Enqurious team as a result of guiding our key clients in achieving a 100% success rate at certifications