
Data Quality Explained: Challenges, Best Practices, and Complete 2026 Guide

Ready to transform your data strategy with cutting-edge solutions?
Imagine this:
A retail company launches a massive festival sale. Ads are live, inventory dashboards look green, and leadership is confident. Orders start pouring in… and then chaos.
- Customers receive wrong products
- Some orders are shipped twice
- Others are cancelled because the items were actually out of stock

What went wrong?
Not the marketing. Not the warehouse. Not even the website.
--> The data.
Product quantities weren’t updated correctly. Customer addresses had missing fields. Duplicate records inflated inventory counts. By the time teams realized the issue, the company had already lost money, trust, and credibility.
This isn’t a rare horror story. This is what happens when data quality is ignored.
And that’s exactly why this guide exists.
So… What Exactly Is Data Quality?
In simple terms:
> Data Quality means how reliable, accurate, and usable your data is for decision‑making.
High‑quality data answers questions like:
- Can I trust this number?
- Is this data complete?
- Does it reflect reality right now?
Low‑quality data makes teams argue instead of decide.
No matter how good the analyst is, bad data ruin everything.
Why Data Quality Is More Important Than Ever in 2026
Data today isn’t just sitting quietly in reports. It actively drives how companies operate, decide, and automate.
In 2026, data is used to:
- Power business decisions
- Train AI and machine learning models
- Personalize customer experiences
- Detect fraud and anomalies
This changes the stakes completely.
Here’s the uncomfortable truth:
> AI trained on bad data doesn’t become intelligent - it becomes confidently wrong.
Poor data quality no longer causes small mistakes. It causes systemic ones.
A single error can now:
- Spread across dashboards
- Influence automated decisions
- Impact thousands (or millions) of users
That’s why data quality has shifted from a backend concern to a business‑critical capability.

Common Problems Caused by Poor Data Quality
Poor data quality rarely announces itself clearly. Instead, it shows up as constant friction.
Teams start questioning numbers. Meetings turn into debates. Reports need explanations before they can be trusted.
In practice, bad data often leads to:
- Leadership seeing different numbers for the same metric
- Marketing targeting the wrong audience
- Finance misreporting revenue
- Operations planning with outdated information
The biggest hidden cost?
> Analysts spend more time fixing data than using it.
When data quality is poor, productivity quietly collapses.
The Core Dimensions of Data Quality (The Big 6)
Data quality is often discussed in abstract terms, but in real systems, issues usually fall into six very concrete buckets. These six dimensions show up repeatedly across industries, tools, and teams.
Let’s break them down with definitions that reflect how these problems actually appear in real data.
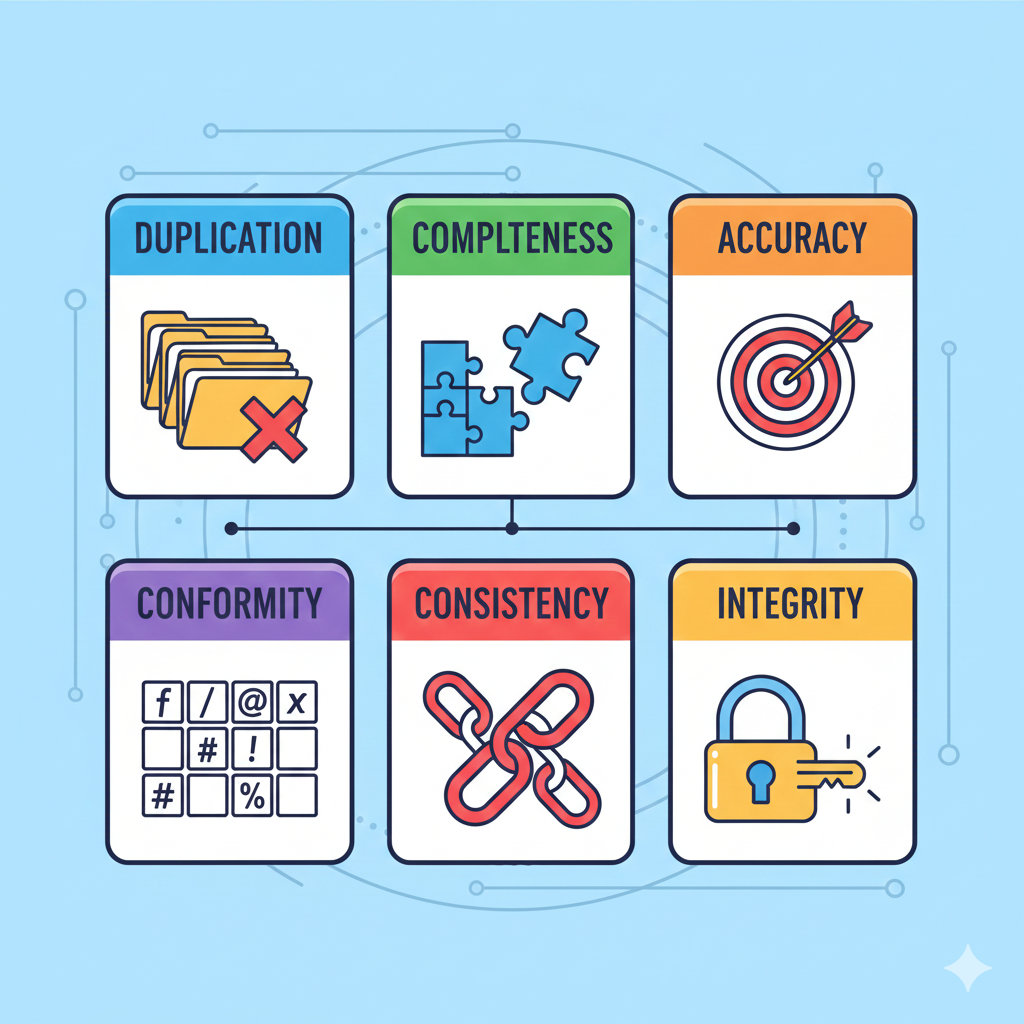
1. Duplication
Definition: Duplication occurs when the same real‑world entity is recorded multiple times in the data.
Instead of one clean record, duplicates fragment information and inflate metrics.
Example:
- The same customer appears multiple times with slightly different names or contact details
Duplication quietly distorts counts, revenue, and customer insights, often without anyone noticing immediately.
2. Completeness
Definition: Completeness measures whether all required data fields are present and populated.
Data can be technically correct and still be unusable if critical information is missing.
Example:
- Customer record without an email or phone number
- Order missing a delivery address
Incomplete data creates blind spots, forcing teams to guess instead of decide.
3. Accuracy
Definition: Accuracy reflects whether data correctly represents real‑world facts.
Inaccurate data may exist perfectly well inside systems, but it does not match reality.
Example:
- Customer ID C123 shows Nagpur in one system
- The same customer shows Jaipur in another system
When accuracy fails, trust collapses, even if the data looks clean on the surface.
4. Conformity
Definition: Conformity ensures data follows standardized formats, naming conventions, and representations.
Here, the issue is not whether data is correct, but whether it is consistent in how it is written.
Examples:
- City stored as Bombay in one record and Mumbai in another
- Leading or trailing white spaces
- Multiple date formats within the same column
- Spelling variations for the same value
Poor conformity makes grouping, filtering, and analysis unreliable.
5. Consistency
Definition: Consistency checks whether relationships and rules hold true across datasets.
Even if individual values look valid, the data may still contradict itself logically.
Example:
- A single order linked to two different customers
Inconsistent data breaks business logic and leads to incorrect joins and reports.
6. Integrity
Definition: Integrity ensures that relationships between tables remain valid, usually enforced through primary and foreign keys.
Integrity issues arise when references point to records that don’t exist or shouldn’t exist.
Example:
- An order referencing a customer ID that does not exist in the customer table
When integrity breaks, downstream systems fail, sometimes silently, sometimes catastrophically.
Types of Data Quality Issues You’ll See Everywhere
No matter the industry, certain data quality issues appear again and again.
You’ll often encounter duplicate records, missing values, incorrect data types, and inconsistent formats. Dates might appear in different formats. IDs that should match don’t. Records that should exist simply don’t.
None of these issues are exotic. That’s what makes them dangerous.
They’re easy to ignore, until they break something important.
Where Do Data Quality Issues Come From?
Spoiler: Not just bad analysts.
Common sources include:
- Manual data entry
- Multiple data sources
- Legacy systems
- Poor data validation rules
- Lack of ownership
- Fast‑moving businesses prioritizing speed over structure
Data breaks silently - until it doesn’t.
Best Practices to Maintain High Data Quality
High‑quality data doesn’t come from heroic last‑minute cleaning. It comes from discipline and structure.
Start by defining clear data standards. Everyone should agree on what valid data looks like and which fields are mandatory.
Next, validate data as early as possible. Catching issues during ingestion is far cheaper than discovering them in reports.
Automation plays a crucial role here. Instead of manually checking datasets, teams monitor freshness, duplicates, and error rates automatically.
Ownership matters just as much. Every important dataset needs someone accountable for it. When ownership is unclear, quality degrades quickly.
Finally, document your data. A metric without context is just a number, and numbers without meaning create confusion.
1. Validate Data Early
Catch issues at ingestion, not during reporting.
Early checks save massive downstream effort.
2. Automate Quality Checks
Use rules to monitor:
- NULL percentages
- Duplicate counts
- Range violations
Automation > manual policing.
3. Assign Data Ownership
Every critical dataset should have an owner.
If everyone owns the data → no one owns the data.
4. Track Data Quality Metrics
Yes, data quality itself should be measured.
Examples:
- % completeness
- Error rate
- Freshness SLA
5. Document Everything
Clear definitions prevent confusion.
A number without context is just a rumor.
Data Quality and Modern Data Stacks
In 2026, data quality is baked into modern platforms:
- Data validation pipelines
- Lakehouse architectures
- Schema enforcement
- Observability tools
- Versioned datasets
Good tools help, but good thinking matters more.
Data Quality in Action:
Banking
In banking, poor data quality doesn’t just cause confusion - it causes risk.
Example:
- A customer’s income is outdated
- Credit score records are inconsistent across systems
Result:
- Wrong credit limits
- Higher default risk
- Regulatory penalties
That’s why banks invest heavily in validation rules and audit trails.
Healthcare
In healthcare, bad data can be life‑threatening.
Example:
- Duplicate patient records
- Missing allergy information
Result:
- Wrong medication
- Delayed treatment
- Compliance violations
Here, data quality is not about dashboards, but it’s about patient safety.
E‑Commerce
Example:
- Product prices differ across systems
- Inventory data is stale
Result:
- Revenue leakage
- Customer refunds
- Trust erosion
This is why modern e‑commerce platforms prioritize real‑time data freshness.
A Beginner’s Data Quality Checklist
Before trusting any dataset, ask:
- Do I know where this data came from?
- Is any critical field missing?
- Does the data make logical sense?
- Is it recent enough for my use case?
- Are there obvious duplicates?
If the answer is “I’m not sure” -- pause before using it.
Difference between Data Quality vs Data Cleaning
Many beginners confuse these.
- Data Cleaning: Fixing existing issues
- Data Quality: Preventing issues from happening again
Cleaning is reactive.
Quality is proactive.
Mature data teams focus on both.
Who Is Responsible for Data Quality?
Short answer: Everyone, but in different ways.
- Engineers ensure correct ingestion
- Analysts validate business logic
- Business teams define what “correct” means
- Leaders enforce accountability
Without shared responsibility, quality always breaks.
Data Quality Is a Mindset
Here’s the truth:
> Data quality isn’t a one‑time task. It’s a habit.
Clean dashboards don’t come from magic.
Reliable AI doesn’t happen by accident.
Trustworthy decisions start with trustworthy data.
If you remember just one thing from this guide, let it be this:
> Great decisions are built on great data, and great data is intentional.
Welcome to the world of data quality. ✨
Ready to Experience the Future of Data?
You Might Also Like
A Snowflake Summit 2026 benchmark revealed a 59x cost gap — open-source models at 440 credits vs. frontier models at 26,000 credits for identical workloads. Learn how CoCo, CoWork, AI Credits, and Cortex Training change enterprise AI strategy.
How a data engineering team replaced manual pipeline work with natural language prompts, using Claude Code and the Databricks AI Dev Kit.

Six errors, 6 hours of debugging, and the permission checklist that finally made Databricks Apps + Genie work. The full lessons-learned guide.

Your Claude Code session isn't lost. It's on disk, in a folder /resume isn't scanning. Here's how to find any session in 30 seconds, with the exact commands.

Scenario based learning replaces tutorials with realistic operational scenarios where engineers develop the hands on judgment classroom instruction cannot produce. How it works and why it matters.
The 2026 data engineering roadmap. SQL, Python, cloud, Airflow, dbt, streaming. What companies actually hire for and how to build a portfolio that gets shortlisted.
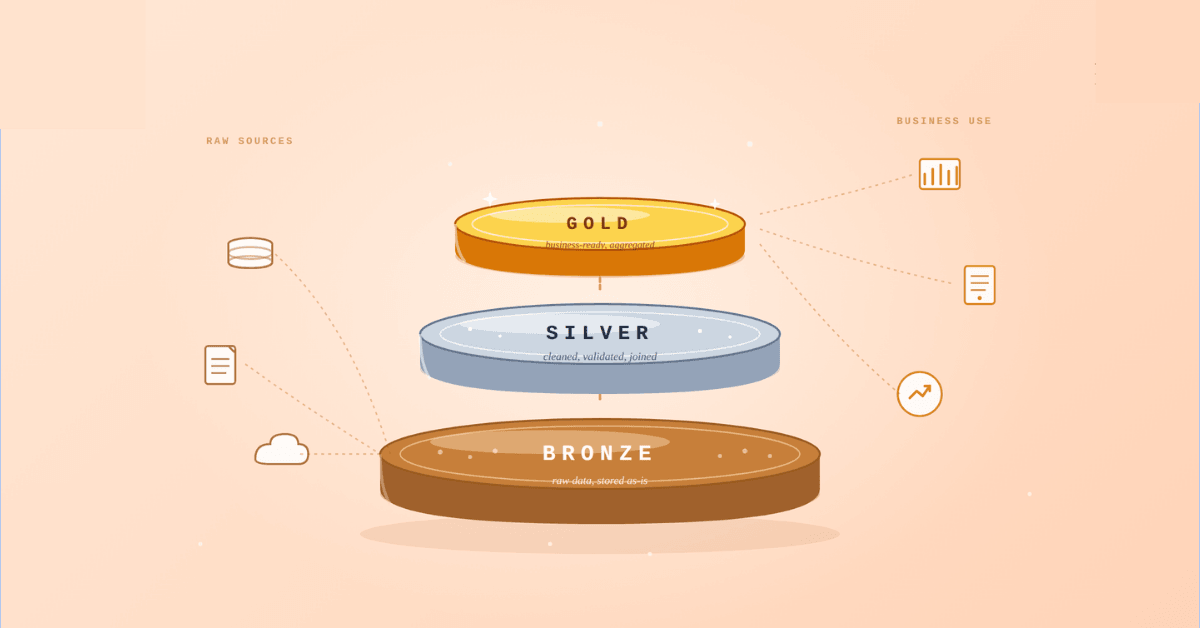
Medallion Architecture splits your data pipeline into Bronze, Silver, and Gold layers so a small business change never forces a full rebuild. Here's why it works.

I was working on a large content repository on Windows, and I needed to version some new work — campaign assets, workshop content, LinkedIn job descriptions, and some file deletions. Simple enough, right? What followed was a two-day journey through some of Git's more obscure corners.

Explore the power of Databricks Lakehouse, Delta tables, and modern data engineering practices to build reliable, scalable, and high-quality data pipelines."

Data doesn’t wait - and neither should your insights. This blog breaks down streaming vs batch processing and shows, step by step, how to process real-time data using Azure Databricks.

This blog talks about Databricks’ Unity Catalog upgrades -like Governed Tags, Automated Data Classification, and ABAC which make data governance smarter, faster, and more automated.

Tired of boring images? Meet the 'Jai & Veeru' of AI! See how combining Claude and Nano Banana Pro creates mind-blowing results for comics, diagrams, and more.
This blog walks you through how Databricks Connect completely transforms PySpark development workflow by letting us run Databricks-backed Spark code directly from your local IDE. From setup to debugging to best practices this Blog covers it all.
Master the bronze layer foundation of medallion architecture with COPY INTO - the command that handles incremental ingestion and schema evolution automatically. No more duplicate data, no more broken pipelines when new columns arrive. Your complete guide to production-ready raw data ingestion

This blog talks about the Power Law statistical distribution and how it explains content virality

An account of experience gained by Enqurious team as a result of guiding our key clients in achieving a 100% success rate at certifications