
Spark Data Ingestion Optimization: Explicit Schemas vs InferSchema
Ready to transform your data strategy with cutting-edge solutions?
- Spark optimization isn't always complex; some tweaks have a huge impact. Inferring schemas forces Spark to scan your data twice, slowing ingestion and inflating cost. Explicit schemas avoid the extra pass and make pipelines faster and cheaper.
Data ingestion is the first step in any data engineering pipeline. A simple choice at this step can make the difference between a pipeline that runs in seconds versus one that takes hours in production.
What I Was Trying to Do,
I wanted to get started with Spark optimization while learning data engineering. Data ingestion is the foundation, so that’s where I started.
I had a transactions dataset of around 7GB in Azure Data Lake Storage. I used the common approach for reading a CSV file with Spark:
transactions_df = spark.read.format("csv") \
.option("header", "true") \
.option("inferSchema", "true") \
.load("abfss://wetrustbidata@adlsstoragedata01.dfs.core.windows.net/transactions.csv")
Just let Spark figure out the data types automatically with inferSchema=True. Simple, convenient, and I don’t have to think about it.
The Execution Time
When I ran the cell, the execution took longer than expected.
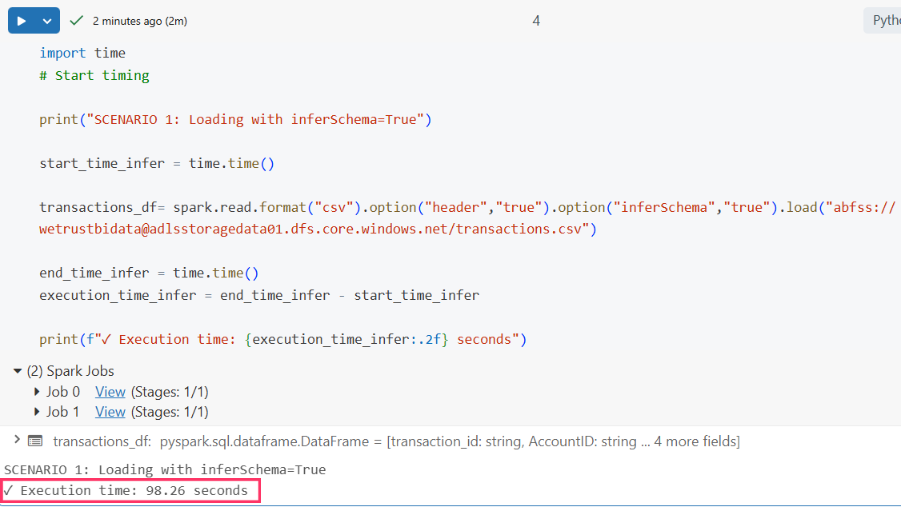
98.26 seconds. Almost 2 minutes just to read a file with a single-node Databricks cluster
This was concerning. Spark is built to handle massive datasets efficiently, so why was a 7GB file taking this long?
That’s when it hit me: If 7GB takes 2 minutes, what happens in production when you’re dealing with terabytes of data?
Minutes turn into hours. Hours turn into SLA breaches. And you’re paying for all that compute time.
Understanding Why This Happens
To understand the performance issue, I looked into how inferSchema=True it works.
When you use inferSchema=True, Spark needs to determine the data types for each column. Here’s what happens:
- First Pass - Schema Inference: Spark reads through your data to understand what type each column should be. Is this column a string? An integer? A date? It samples the data to make these decisions.
- Second Pass - Actual Data Load: Now that Spark knows the schema, it reads the data again to actually load it into a DataFrame.
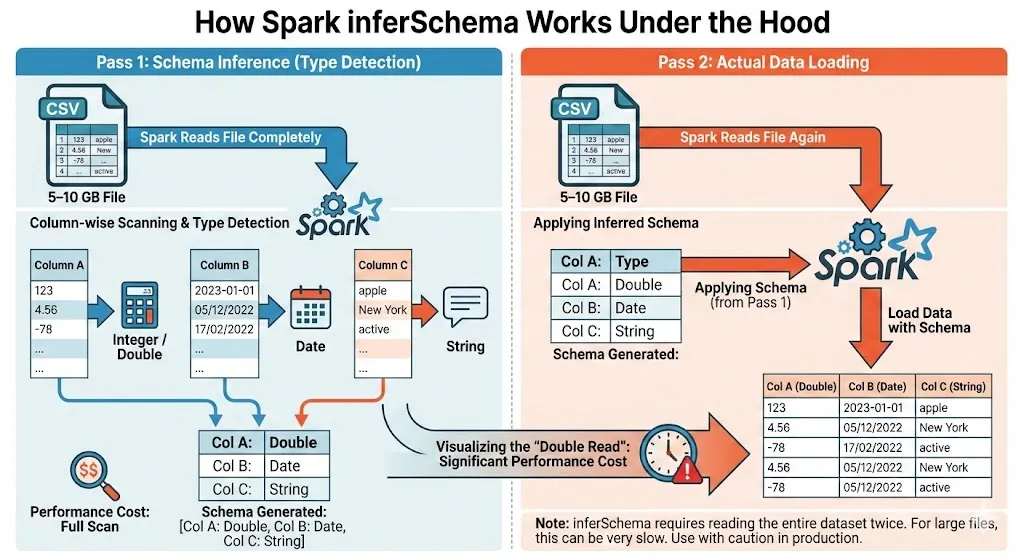
Spark is reading your data twice.
To verify this, I checked the Spark Jobs section in Databricks.
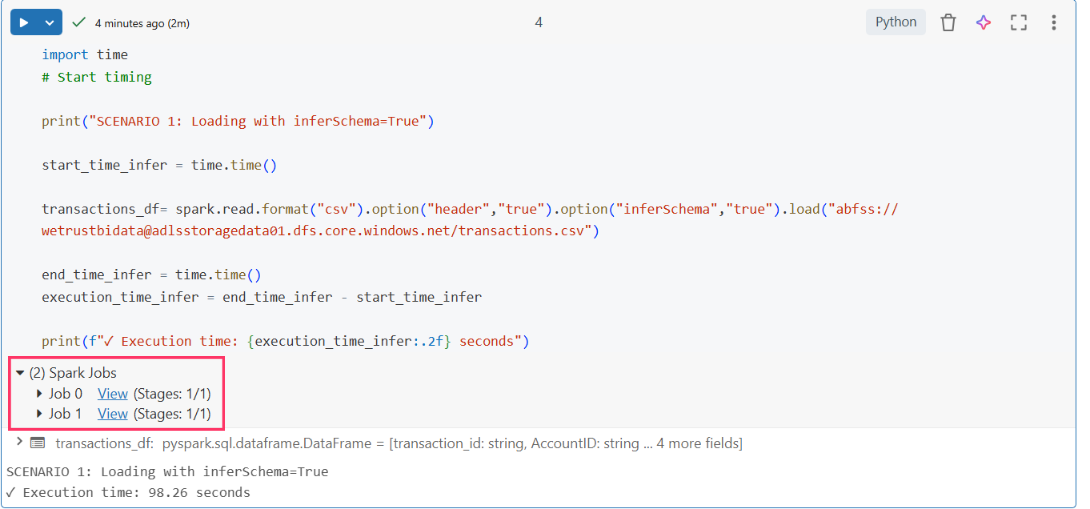
See that? (2) Spark Jobs. Two separate jobs - Job 0 and Job 1.
Let me show you what each job is doing:

- Stage 0: This is the schema inference job. It took 1 second and scanned 64 KiB of data to figure out the schema.
- Stage 1: This is the actual data load. It took 1.5 minutes and read 6.8 GiB - the full dataset.
So the total time? 1.5 minutes for loading + overhead for inference = ~2 minutes total.
The problem is clear: Spark has to do two jobs when it should only need to do one.
The Solution: User-Defined Schema
Instead of letting Spark infer the schema, we can define it explicitly upfront.
This is called a User-Defined Schema. In Databricks documentation, this approach is also referred to as schema-on-read with explicit schema definition.
The difference:
- inferSchema: Spark scans the data to determine column types
- User-Defined Schema: Spark uses the provided schema and directly loads the data
Here’s the implementation. First, define the schema manually:
from pyspark.sql.types import StructType, StructField, StringType, DoubleType, DateType
# Define schema explicitly
transactions_schema = StructType([
StructField('transaction_id', StringType(), True),
StructField('AccountID', StringType(), True),
StructField('TransactionOperation', StringType(), True),
StructField('transaction_type', StringType(), True),
StructField('transaction_date', DateType(), True),
StructField('Amount', DoubleType(), True)
])
Then I loaded the data with this schema:
transactions_df = spark.read.format("csv") \
.option("header", "true") \
.schema(transactions_schema) \ .load("abfss://wetrustbidata@adlsstoragedata01.dfs.core.windows.net/transactions.csv")
I created a fresh notebook to get a new Spark session and ran this code.
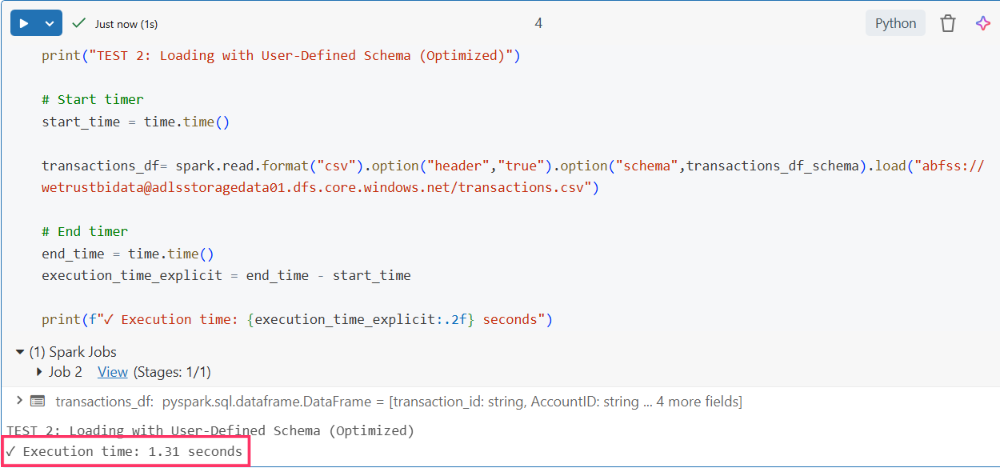
1.31 seconds.
The execution time dropped from 98 seconds to 1.31 seconds - a 75x performance improvement.
Verifying the Optimization
To verify this optimization, I checked the Spark Jobs section again:
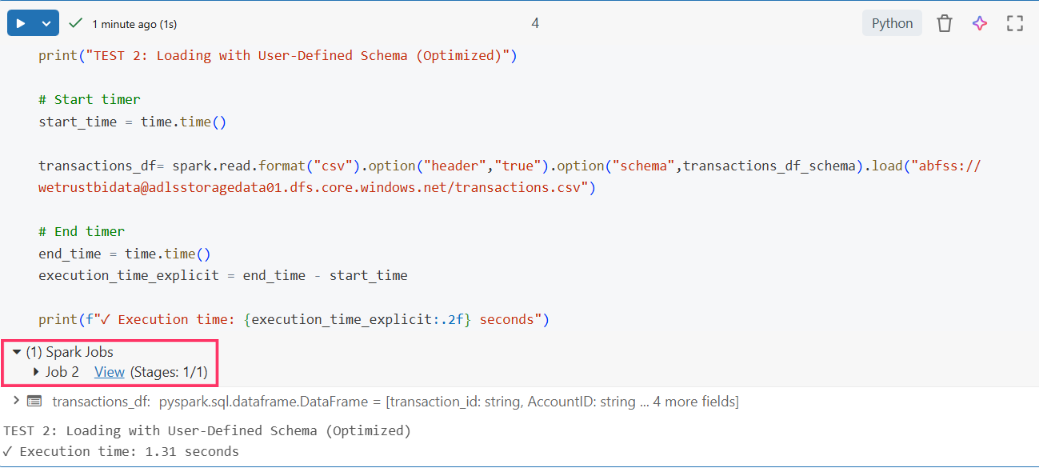
(1) Spark Jobs. Just one job this time. Job 2.
And when I looked at the stages:

Only Stage 2 - the data load stage. It took 0.2 seconds and read 64 KiB.
Wait, only 64 KiB? That’s because this stage is just the initial scan setup. The actual data reading happens during the task execution, which is completed in just over 1 second total.
The key difference: No Stage for schema inference. Spark skipped that entirely because I already told it what the schema was
The difference is clear:
- No inference job needed - Spark already knows the data types
- Single job - Just load the data, and you’re done
- 75x faster - From almost 2 minutes to just over 1 second
What Does This Mean for Production?
This was just 7GB of data. But in production, data engineers work with much larger datasets.
Let’s say you’re working with a 1TB dataset. If it scales linearly:
- inferSchema: ~14,000 seconds = ~3.9 hours
- User-Defined Schema: ~187 seconds = ~3 minutes
You save almost 4 hours. And that’s just for one file, one load.
Now imagine you’re running this daily. Or even hourly. The time (and cost) adds up fast.
The Cost Impact
In cloud environments like Databricks, you pay for compute time. More time = more money.
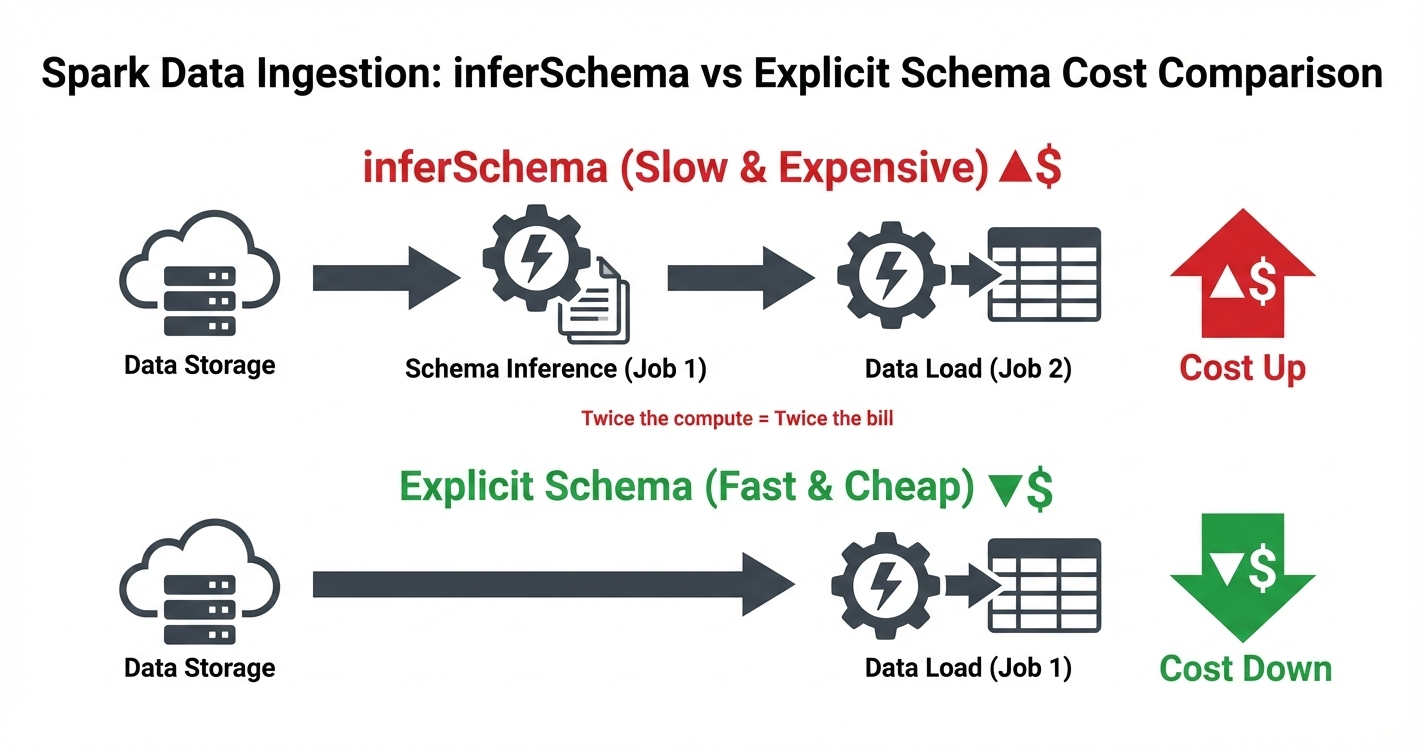
With inferSchema=True, you’re:
- Paying for schema inference that you don’t need
- Scanning data twice instead of once
- Running your cluster 75x longer
For production pipelines that run regularly, this can mean thousands of dollars in wasted compute costs every month.
When Should You Use inferSchema vs User-Defined Schema?
Both approaches have their use cases.
Use inferSchema when:
- You’re exploring data and don’t know the schema yet
- You’re working with small files (< 100MB) where speed doesn’t matter
- The schema keeps changing, and you need flexibility
- You’re doing a quick, one-off analysis in a notebook
Use User-Defined Schema when:
- You’re building production pipelines
- You’re working with large files (> 1GB)
- The schema is stable and known
- Performance matters
- You’re running scheduled jobs
How to Get the Schema If You Don’t Know It
If the schema is unknown, you can use inferSchema once on a small sample to discover it, then use that schema definition in production code.
# Step 1: Run this once to see the schema
sample_df = spark.read.format("csv") \
.option("header", "true") \
.option("inferSchema", "true") \
.load("path/to/your/file.csv")
# Step 2: Print the schema
sample_df.printSchema()
# Step 3: Copy the output and create your StructType definition
# Use that in your production code
Or, if you have documentation about your data source (like a database schema or API documentation), just map those types to Spark types directly.
Key Takeaways
Defining schemas explicitly instead of using inferSchema=True provides significant benefits:
- 75x faster data loading (98 seconds → 1.3 seconds)
- Reduces Spark jobs by 50% (2 jobs → 1 job)
- Saves hours of compute time in production
- Reduces cloud costs significantly
This optimization demonstrates that performance improvements don’t always require complex tuning or advanced configurations. In this case, explicitly defining the schema eliminates unnecessary computation.
For production data pipelines, defining schemas explicitly is a best practice that improves performance with every pipeline execution.
When using inferSchema=True, Consider whether explicitly defining the schema would be more efficient for your use case.
You Might Also Like
Skill gaps in data teams rarely show up in surveys or certifications. They show up when someone calls pd.read_csv on a .xlsx file. Three methods to make competence observable, not self-reported.

A practical walkthrough of how I reduced heavy batch workloads using Change Data Feed (CDF) in Databricks. This blog shows how CDF helps process only updated records, cutting compute costs and boosting pipeline efficiency.

Why DELETE isn’t enough under GDPR, and how Time Travel can make sensitive data reappear unless VACUUM is used correctly.

A complete guide to building a future-ready L&D team in 2025. Explore the roles, skills, structure, and AI-driven strategies that drive real business impact.

Learn how to bridge the digital skills gap with effective upskilling strategies. Discover how to foster a culture of continuous learning, personalize training with AI, and focus on future-ready skills.

Discover 5 key strategies to overcome upskilling and reskilling challenges in the age of AI. Learn how to build a future-ready workforce with personalized learning, cross-functional collaboration, and real-world application.

Explore the key differences between LXP and LMS platforms and learn which is best for your business in 2025. Discover how AI-driven learning systems can boost employee engagement and upskill your workforce for the future.

Discover 6 powerful ways to upskill employees and future-proof your workforce in the age of AI and data. Learn how leading organizations are adapting learning strategies to stay ahead.

Explore the difference between reskilling and upskilling and why it matters for career growth and organizational success. Learn how reskilling helps workers pivot to new roles and how upskilling enhances current skills to stay competitive in today's fast-changing job market.

Explore the 6 core adult learning principles and how they can transform your training programs. Learn how to apply these principles for better engagement, retention, and real-world application, ensuring meaningful learning experiences for adult learners.

Discover the 9 key components of an effective learning experience and how they drive better engagement, retention, and real-world application. Learn how organizations can implement these elements to create impactful learning journeys.

Boost your Business Intelligence skills in 2025 with 25 hands-on exercises that cover data analysis, visualization, SQL, and more. Perfect for professionals looking to sharpen their BI expertise and stay ahead in the competitive job market.

Learn about Learning Management Systems (LMS), their key benefits, and popular examples like Moodle, Google Classroom, and Enqurious. Discover how LMS platforms are revolutionizing education and training for businesses and schools.

Discover how AI is transforming workplace learning and development by personalizing training, delivering real-time feedback, and aligning learning with business goals to drive workforce excellence and growth.

Discover why a Capstone Project is essential in 2025. Explore how it bridges the gap between theory and practice, enhances problem-solving skills, provides industry experience, and prepares students for real-world challenges. Learn how capstone projects are shaping future careers.

In today’s rapidly evolving job market, the value of evidence-based skills has never been more critical. As industries shift and technology transforms how we work, the need for tangible proof of competencies has become paramount.

In today’s rapidly evolving technological landscape, one skill stands out above all others: learnability. Learnability, often described as the ability to continuously acquire new skills and adapt to change, is no longer just an advantage but a necessity.

To build a future-ready workforce, companies need to rethink talent strategies. Start by developing a data-driven talent system to align key roles with best-fit talent. Invest in AI training now to stay ahead, and shift hiring practices to focus on skills, not just job titles.

At Enqurious, we understand the importance of empowering workforces with the right skills to navigate emerging challenges. Enqurious works as a strategic partner to supplement and enhance L&D Teams.

Understanding how variables work together can supercharge your marketing strategy.

Marketing Effectiveness: Strategies, Channels, and ROI Maximization

The transformative journey of the energy sector: from outdated practices to a data-driven revolution.

Enhancing Readability for Effective Learning and Development

This guide helps to understand what elements come together to make or break a visual

Thoughtfully crafted instruction design with drops of ambiguity and room for creative thinking makes the learning experience more enjoyable and “real world”.

Even after putting the best of the content, infrastructure and people, the gap between the intention of organizations to foster a culture of learning and the actual implementation and adoption of learning initiatives by employees keeps on widening.

Understanding why it is so important to nurture self driven learners in a fast paced technology world

Leveraging data to design better and efficient L&D strategy for organization success