
Medallion Architecture: Why Most Data Pipelines Break Without It
Ready to transform your data strategy with cutting-edge solutions?
The Problem: When "Simple" Stops Scaling
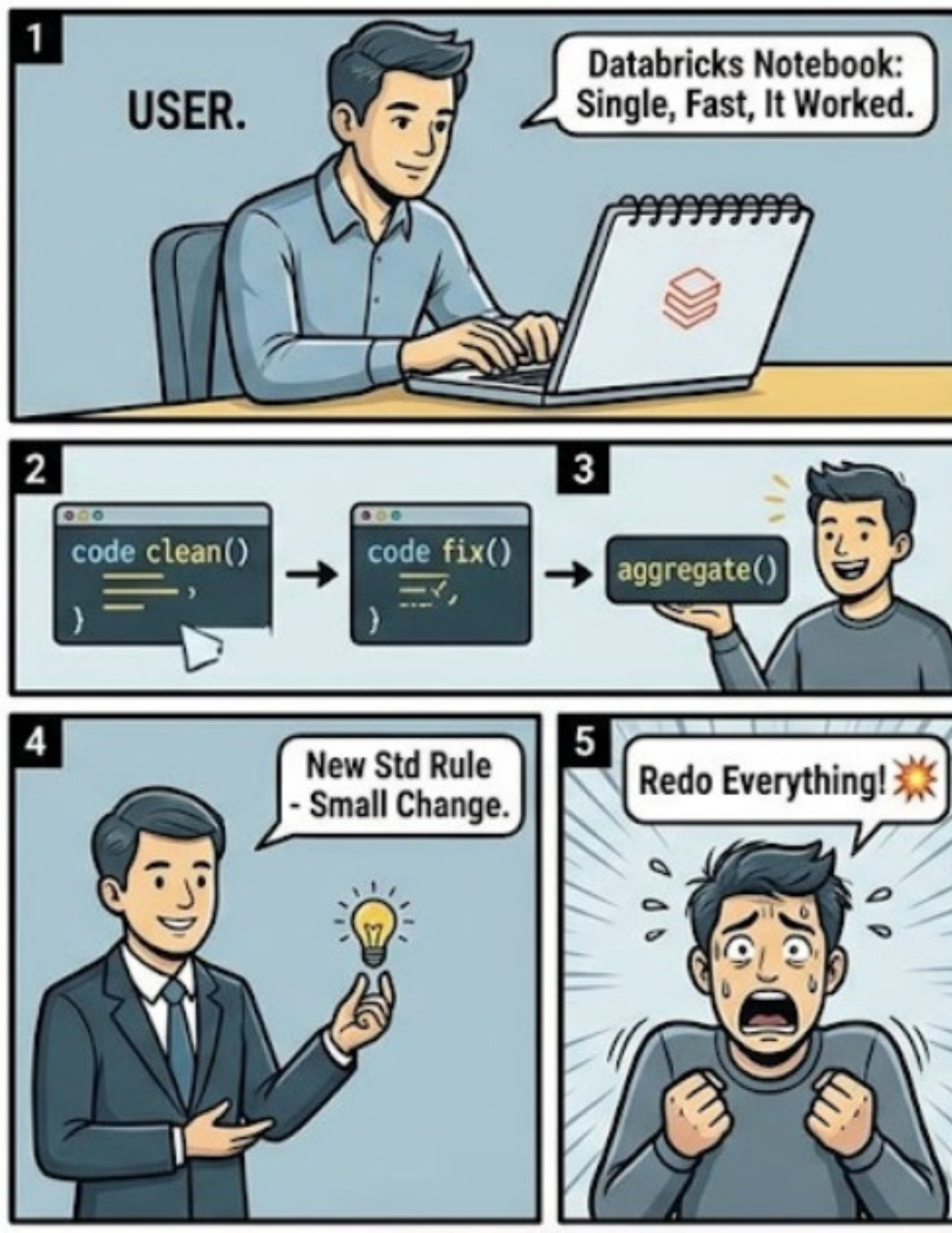
When I started working with Databricks, I built my entire pipeline in a single notebook. Extract the data. Clean it. Fix quality issues. Build aggregations. Everything in one place. It was simple. It was fast. It worked.
Until one day, it didn't.
The business came back with a small change. A new standardization rule.
Nothing major. But implementing it wasn't simple anymore. Because that one notebook wasn't just doing one job. It was doing everything. Which meant to make a small change, I had to go back, reprocess everything, and rebuild the entire flow from scratch. What should have taken minutes turned into hours of rework. And that's when it hit me. The problem wasn't the logic. It was the lack of structure. I wasn't making a change. I was restarting the system.
Why Most Data Pipelines Eventually Break
In the beginning, every pipeline looks efficient. You take raw data → process it → generate outputs. Done. But as systems grow:
Business logic changes
Data definitions evolve
More teams start depending on the same data
And suddenly, your pipeline becomes fragile. Because everything is tightly coupled. There's no clear separation between:
Raw data
Cleaned data
Business ready data
So even a small change forces you to touch everything. Most pipelines are built to move data. Not to adapt to change.
The Shift: From Processing Data to Structuring It
Most teams try to solve this by making pipelines faster. But speed isn't the real problem. Structure is. Because data isn't static. It evolves. And if your pipeline doesn't account for that, you don't fix things. You rebuild them.
What you actually need is a system where data improves step by step, without breaking everything downstream.
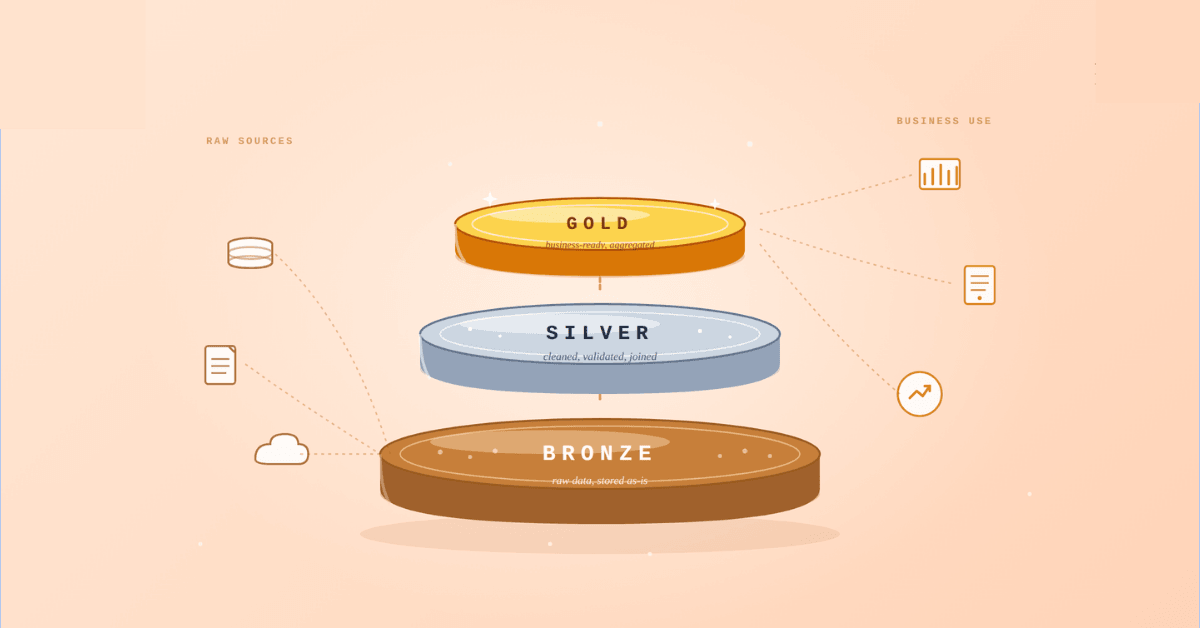
What is Medallion Architecture?
Medallion Architecture is a way to structure data pipelines into layers of refinement:
Bronze → Raw data
Silver → Cleaned and structured data
Gold → Business ready data
Instead of doing everything in one flow, you break it into stages with clear responsibilities. Each layer builds on the previous one. Each layer serves a specific purpose. And this is where things start to change. Because now, when something needs to be updated, you don't rebuild everything. You don't go back and extract raw data again. You don't redo all your cleaning steps. You simply go to the relevant layer, make the change, and let the rest of the pipeline flow forward.
For example:
A change in standardization logic? → Update Silver
A change in reporting logic? → Update Gold
That's it. Small change. Small impact. Instead of: small change → full pipeline rebuild. And that's the real shift. You're no longer just processing data. You're structuring how it evolves.
Let's Break This Down
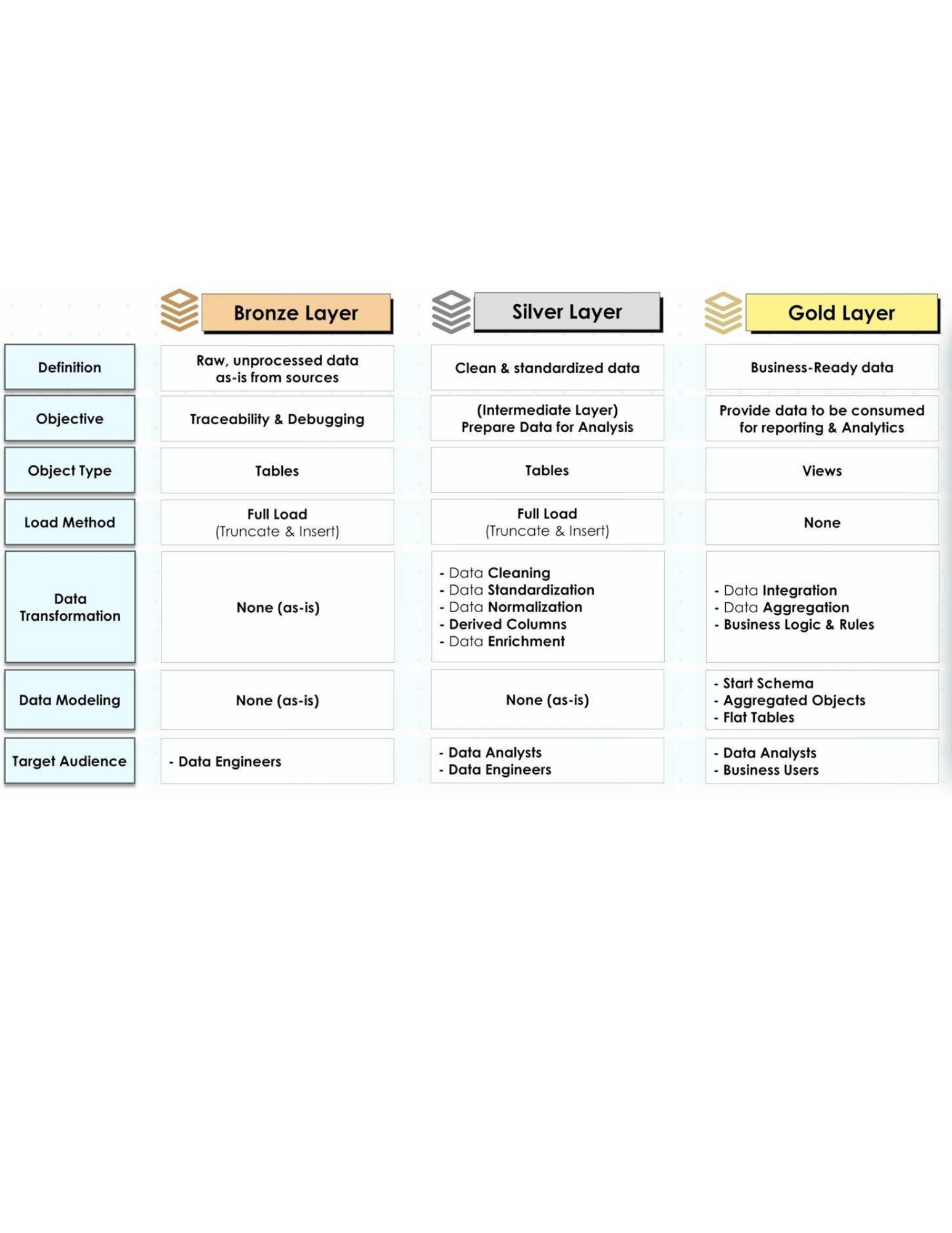
Bronze Layer: Store Reality
This is where data first enters your system. And the rule here is simple: Don't try to fix anything. Data can come from anywhere:
Streaming applications
Excel or CSV files
Databases
APIs
Third party systems
Different formats. Different structures. Different levels of quality. And that's okay. Because in the Bronze layer, you store data exactly as it arrives.
No transformations
No filtering
No assumptions
Why? Because this layer is not about usability. It's about preservation.
Why This Matters
Let's say you're receiving streaming data from an application. But the source system only retains data for 1 day. Now imagine this:
A new business request comes in after 3 to 4 days
You need to reprocess historical data
But that data is gone.Forever.
Unless you had stored it. That's exactly what Bronze protects you from.
What Bronze Actually Gives You
A complete historical record
The ability to replay pipelines
A fallback when things break
Protection against data loss
Bronze doesn't make data better. It makes data available when you need it most.
Example
Raw order data from multiple systems
Same fields in different formats
Duplicate or incomplete records
Everything is stored as is. Because later, when logic changes, you don't go searching for data again. You already have it.
🥈 Silver Layer: Build Trust (Where Data Becomes Reliable)
This is where raw data starts making sense.
In Bronze, you stored everything. In Silver, you start fixing it.
Remove duplicates
Handle missing values
Standardize formats (dates, currencies, units)
Join data from multiple sources
Apply business rules
Now the focus shifts from "Do we have the data?" to "Can we trust this data?"
Why This Matters
Let's go back to your problem. The business asked for a new standardization rule. Earlier, your entire pipeline was in one notebook. So even a small change forced you to redo everything. Now imagine this with Silver in place:
Your cleaning logic lives here
Your standardization rules live here
So when something changes, you don't touch raw data. You don't rebuild final outputs. You simply update the Silver layer logic. And everything downstream adjusts automatically.
What Silver Actually Gives You
Clean, consistent datasets
Reusable transformation logic
A single place for data quality rules
Isolation from raw data complexity
Silver is where data quality is not just fixed. It's designed.
Example
Convert all date formats into one standard
Remove duplicate transactions
Ensure customer IDs match across systems
Merge orders + payments + customer data
Now you have one reliable dataset. Not perfect for business yet, but stable enough to build on.
🥇 Gold Layer: Deliver Value (Where Data Becomes Insight)
This is where data becomes useful for the business. You're no longer fixing data. You're shaping it for decisions.
Aggregate metrics (sales, revenue, growth)
Create reporting tables
Build business friendly data models
Optimize for fast queries
This is what powers:
Dashboards
Reports
Business insights
Why This Matters
Imagine your leadership team is tracking:
Daily revenue
Region wise performance
Customer trends
They don't need raw data. They don't need cleaned tables. They need answers. That's what Gold provides. And here's the important part. If something changes in business logic, you don't fix it here. You go back to Silver, update the logic, and let Gold refresh automatically.
What Gold Actually Gives You
Business ready datasets
Faster queries and dashboards
Consistent metrics across teams
A single source of truth (SSOT)
Gold doesn't fix data. It delivers decisions.
Example
Daily sales summary table
Monthly revenue trends
Region wise performance dashboards
Customer segmentation datasets
This is the layer your business interacts with.
🔗 How These Layers Work Together
Individually, each layer has a purpose.
But the real power of Medallion Architecture comes from how these layers work together.
Think of it as a flow:
Data is captured in Bronze
Refined in Silver
Served through Gold
But unlike a single notebook pipeline, this isn't happening "on the go". At each step, data is persisted. It is stored. It exists. It can be reused. Not something that runs once and disappears.
Layer by Layer Flow
Bronze → Silver: Raw data is cleaned and standardized
Silver → Gold: Clean data is transformed into business ready insights
And at each step, the output is saved before moving forward.
Why This Changes Everything
This is the difference most people miss. In a typical pipeline, data flows through steps but isn't stored in between. So when something changes, you restart everything.
But with Medallion Architecture:
Bronze data is stored
Silver data is stored
Gold data is stored
Each layer becomes a checkpoint.
So now:
You don't lose intermediate work
You don't repeat transformations
You don't depend on re extracting data
Your data is no longer "in motion". It's available at every stage.
What This Enables
Because each layer is persisted:
You can debug easily
You can reuse datasets
You can update specific steps
You can scale without breaking things
Most importantly, you move from a pipeline that runs to a system that lasts.
How These 3 Layers Actually Change Everything
Let's go back to that moment. A small business change broke your entire pipeline. Not because the logic was wrong, but because everything was tightly coupled. Now look at the same situation with Medallion Architecture.
🔁 The Same Scenario, Different Outcome
Raw data already exists → Bronze
Cleaning logic is isolated → Silver
Final outputs are built on top → Gold
Now when the business asks for a change:
You don't re extract data
You don't rebuild everything
You don't touch every step
You simply update one layer. And everything else flows forward. The pipeline doesn't restart. It adapts.

🧠 What This Structure Really Solves
It's not just about layers. It solves the problems that silently break most data systems:
Rework. No more repeating extraction and cleaning again and again
Fragility. Changes don't ripple across the entire pipeline
Inconsistency. One place for logic → one version of truth
Data Loss. Raw data is always preserved and accessible
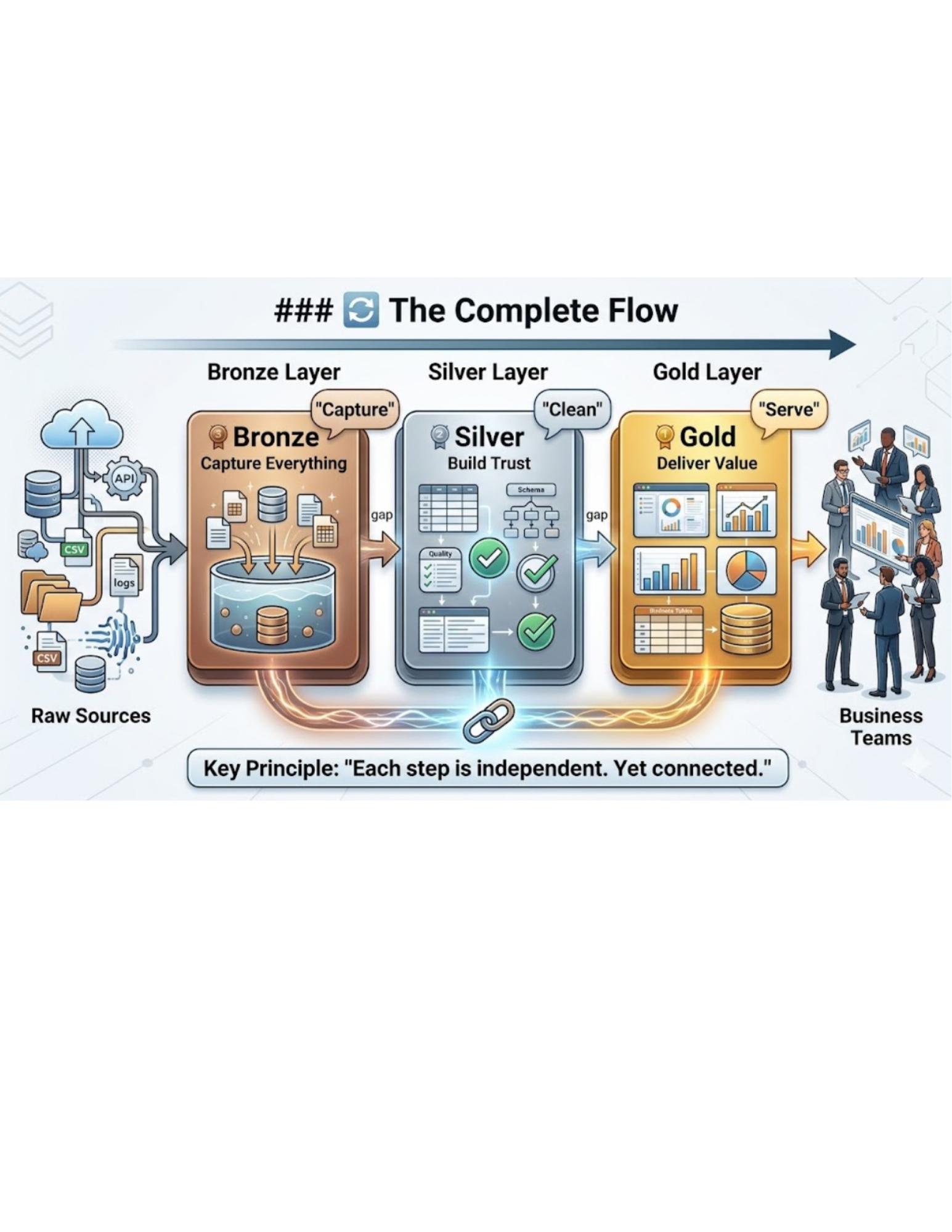
🔄 The Complete Flow
Raw Sources → Bronze → Silver → Gold → Business Teams
Or in simple terms:
Capture → Clean → Serve
But the real difference is this: Each step is independent. Yet connected.
💡 Final Thoughts
Medallion Architecture is often explained as "a 3 layer model". But that's not what makes it powerful.
This is:
It turns your pipeline from a one time process into a system that can handle change. Good pipelines move data. Great pipelines handle change.
Ready to Experience the Future of Data?
You Might Also Like
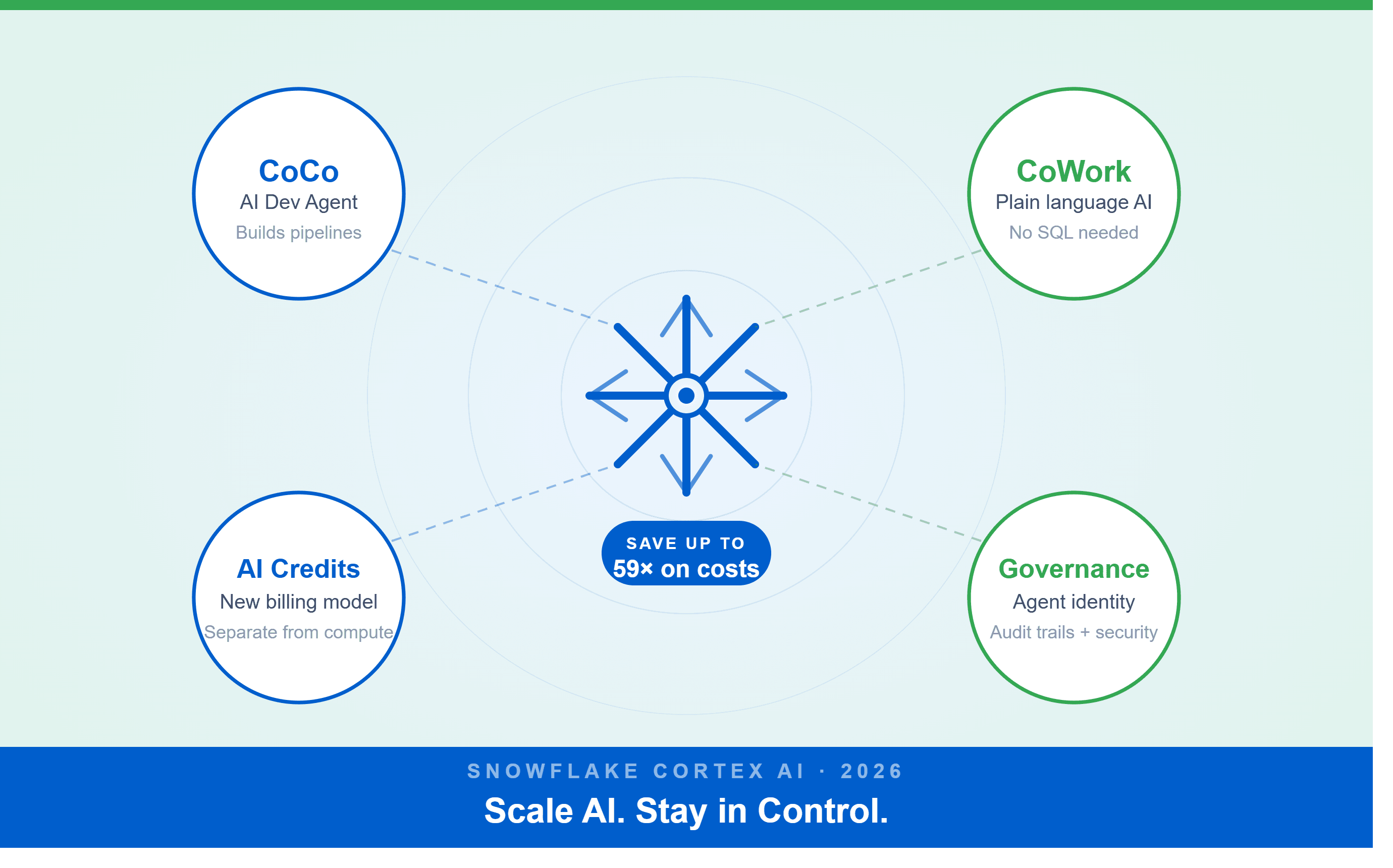
A Snowflake Summit 2026 benchmark revealed a 59x cost gap — open-source models at 440 credits vs. frontier models at 26,000 credits for identical workloads. Learn how CoCo, CoWork, AI Credits, and Cortex Training change enterprise AI strategy.
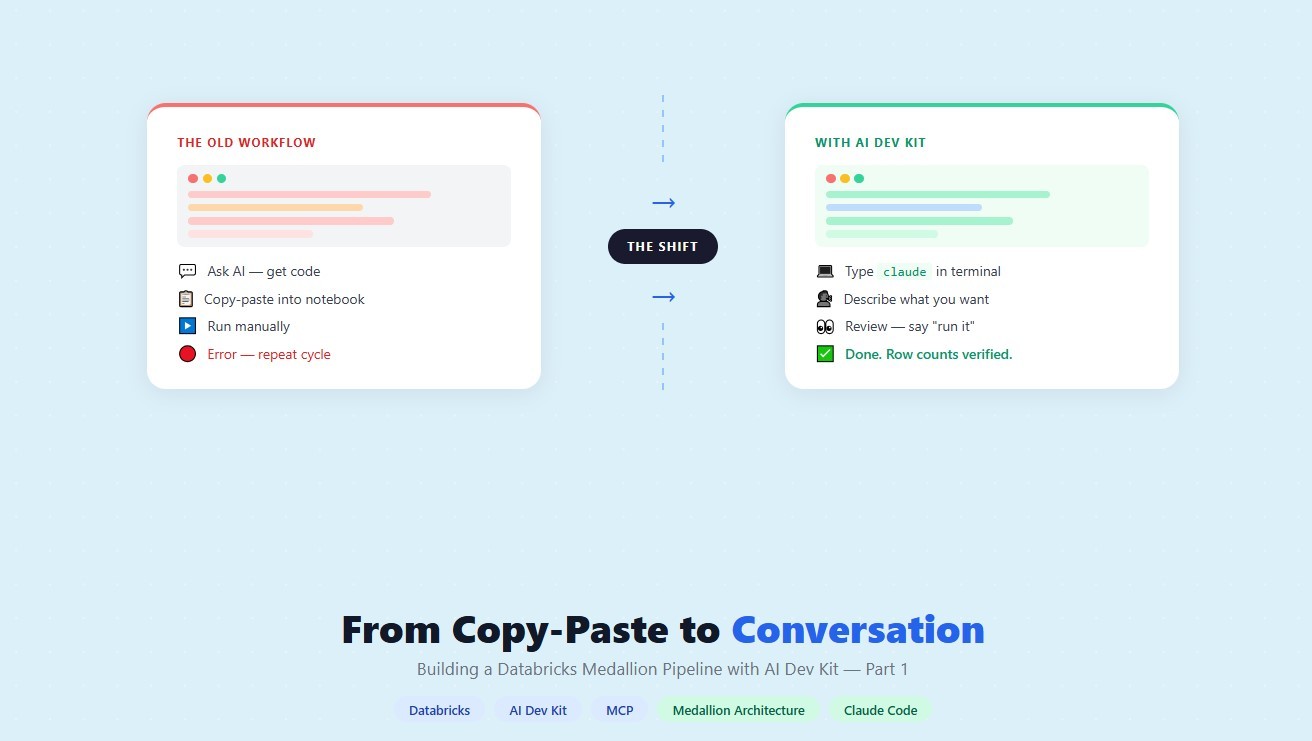
How a data engineering team replaced manual pipeline work with natural language prompts, using Claude Code and the Databricks AI Dev Kit.

Six errors, 6 hours of debugging, and the permission checklist that finally made Databricks Apps + Genie work. The full lessons-learned guide.

Your Claude Code session isn't lost. It's on disk, in a folder /resume isn't scanning. Here's how to find any session in 30 seconds, with the exact commands.

Scenario based learning replaces tutorials with realistic operational scenarios where engineers develop the hands on judgment classroom instruction cannot produce. How it works and why it matters.
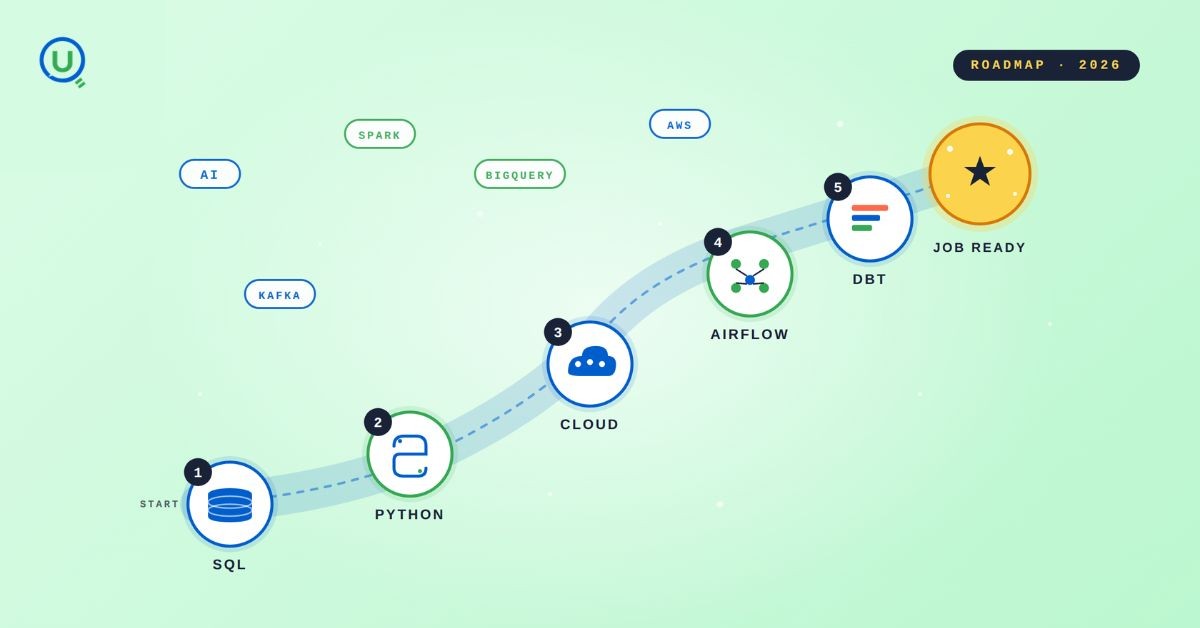
The 2026 data engineering roadmap. SQL, Python, cloud, Airflow, dbt, streaming. What companies actually hire for and how to build a portfolio that gets shortlisted.

I was working on a large content repository on Windows, and I needed to version some new work — campaign assets, workshop content, LinkedIn job descriptions, and some file deletions. Simple enough, right? What followed was a two-day journey through some of Git's more obscure corners.

A complete beginner’s guide to data quality, covering key challenges, real-world examples, and best practices for building trustworthy data.

Explore the power of Databricks Lakehouse, Delta tables, and modern data engineering practices to build reliable, scalable, and high-quality data pipelines."

Data doesn’t wait - and neither should your insights. This blog breaks down streaming vs batch processing and shows, step by step, how to process real-time data using Azure Databricks.

This blog talks about Databricks’ Unity Catalog upgrades -like Governed Tags, Automated Data Classification, and ABAC which make data governance smarter, faster, and more automated.

Tired of boring images? Meet the 'Jai & Veeru' of AI! See how combining Claude and Nano Banana Pro creates mind-blowing results for comics, diagrams, and more.
This blog walks you through how Databricks Connect completely transforms PySpark development workflow by letting us run Databricks-backed Spark code directly from your local IDE. From setup to debugging to best practices this Blog covers it all.
Master the bronze layer foundation of medallion architecture with COPY INTO - the command that handles incremental ingestion and schema evolution automatically. No more duplicate data, no more broken pipelines when new columns arrive. Your complete guide to production-ready raw data ingestion

This blog talks about the Power Law statistical distribution and how it explains content virality

An account of experience gained by Enqurious team as a result of guiding our key clients in achieving a 100% success rate at certifications