
Data Engineering Roadmap 2026: What Companies Actually Hire
Ready to transform your data strategy with cutting-edge solutions?
Most data engineering roadmaps will tell you to learn SQL, then Python, then Spark. That advice is not wrong. It is just incomplete, and it lags behind what hiring managers are actually looking for in 2026.
The bar has moved. Companies are not just looking for engineers who can write a pipeline. They are looking for engineers who can design one, defend their decisions, and own the outcome. Whether you're starting out, transitioning into data, or rebuilding your roadmap as a fresher, this guide reflects what companies are actually hiring for in 2026, what your portfolio needs to include, and how AI has reshuffled the skill priority list.
Quick Answer
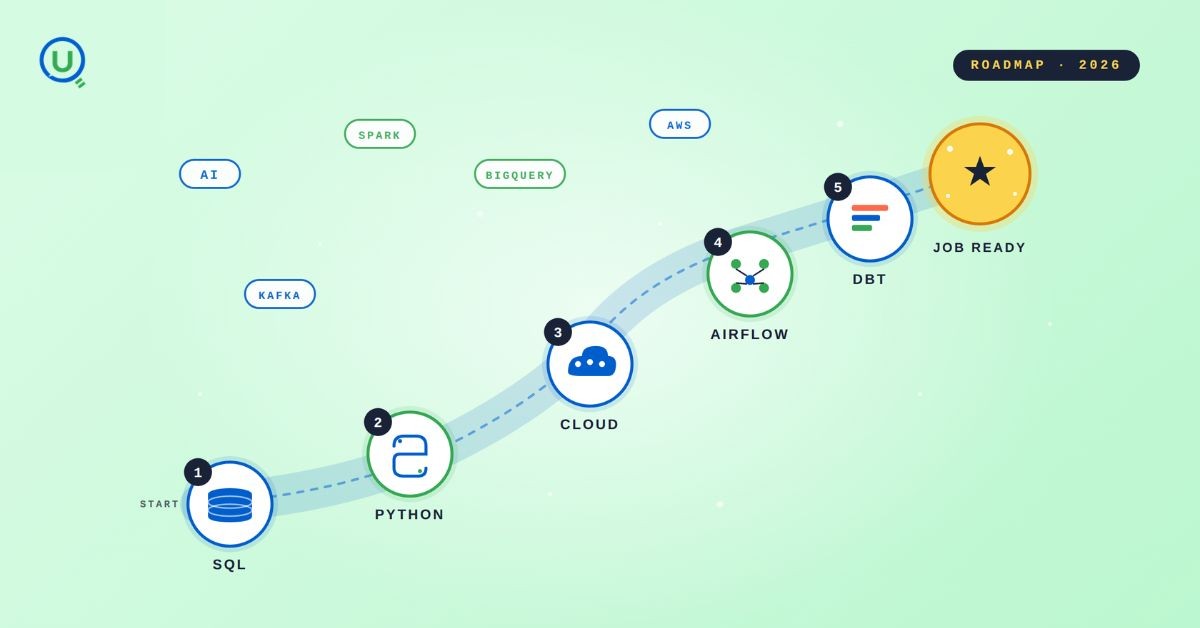
The 2026 data engineering core stack:
SQL with optimization depth
Python for pipeline work
One cloud platform, chosen by depth not breadth
Airflow for orchestration
dbt for transformation
Working understanding of streaming concepts
Beyond tools, companies evaluate:
System design thinking
Data quality ownership
The ability to defend architectural decisions
A strong portfolio project matters more than a certification.
How the Data Engineering Role Has Changed in 2026
The title says "Data Engineer" but the expectation in many teams now leans toward "Data Platform Engineer." Companies want people who understand the full lifecycle of data: how it gets ingested, how it gets modelled, how it gets served, and how the whole system behaves under pressure.
Two things are driving this shift:
Tooling has matured. Managed cloud services handle a lot of the infrastructure work that DEs used to do manually.
AI has automated a significant portion of low value, repetitive coding tasks. A majority of professional developers now report using AI tools in their day to day workflows, and data engineering is no exception.
What remains is the thinking work: architecture decisions, cost trade offs, data quality ownership, and cross functional collaboration.
For someone entering the field today, this is good news. Depth and problem solving matter more than memorising syntax. But it also means the threshold for what counts as real experience is higher.
The 2026 Data Engineering Skill Stack
Here are the six core skills that matter in 2026, and what companies actually test for in each.
1. SQL
SQL is the entry point for any data engineer career path. But in 2026, knowing SELECT and GROUP BY is not enough. Hiring managers expect you to understand query optimisation, window functions, CTEs, and how your query behaves on large datasets.
What a weak SQL answer looks like vs a strong one:
Weak: "I wrote a query to get total sales by region using GROUP BY."
Strong: "I wrote a GROUP BY query, but noticed it was doing a full table scan on 50 million rows. I rewrote it using a partitioned CTE and brought query cost down significantly. The trade off was slightly more complex logic, which I documented."
The difference is not syntax. It is the ability to explain why you wrote the query the way you did and what happens at scale.
2. Python for Data Engineering
Python in a DE context means pipeline scripting, API ingestion, and PySpark. The distinction is not about the tools you use. Notebooks are used widely across modern platforms including Databricks. The distinction is about what your code does and whether it is production ready. Production DE work means modular, testable code with proper error handling, whether you write it in a notebook or an IDE.
Tutorial Python is linear and assumes everything works. Production Python handles failures gracefully and can be rerun without creating duplicates. Your portfolio should reflect the latter.
3. Cloud Platforms
AWS, GCP, and Azure all have strong market presence. Trying to learn all three at the surface level is a common mistake. Depth in one platform is far more valuable in an interview than shallow familiarity with all three.
Interviewers probe for the details: IAM roles and permissions, cost optimisation decisions, when to use one service over another, and how you would architect a solution given specific constraints. Cloud depth is consistently one of the top factors that separates shortlisted candidates from filtered ones in senior DE roles.
4. Airflow and Orchestration
Apache Airflow, originally built and open sourced by Airbnb to manage their internal data workflows, remains the most widely used orchestration tool across enterprise data teams. What matters is not just knowing how to write a DAG but understanding task dependencies, failure handling, retries, and alerting strategies.
A poorly designed DAG tells a hiring manager a lot. If your pipeline has no failure handling and no monitoring, it signals that you have never had to maintain something in production.
5. dbt
If SQL is the foundation, dbt is the layer that separates pipeline writers from data modellers. Models, tests, and documentation are not optional extras. They are the standard.
The common mistake freshers make is treating dbt as "just SQL with a wrapper." It is actually a software engineering discipline applied to analytics. The engineers who understand that get hired.
6. Streaming and Real Time Pipelines
LinkedIn created Apache Kafka to handle billions of events per day across their platform. Uber processes millions of real time ride and payment events using Kafka at the core of their streaming infrastructure. But most early career DEs do not need Kafka expertise on day one.
What you do need to understand is when data needs to be processed in real time versus batch, and why that decision matters for architecture and cost.
For a concrete example of what a modern streaming pipeline looks like in production, the breakdown on Streaming with Azure Databricks walks through it step by step.
AI in Data Engineering in 2026
The conversation around AI in data engineering has shifted from "is it coming for our jobs" to "how do I use it well." Most professional developers do not see AI as a replacement. The concern is not replacement. It is relevance.
AI handles the boilerplate: query generation, scaffolding code, documentation drafts. What it does not replace is judgment. System design decisions, data quality ownership, and debugging under pressure still require a human who understands the system. And as AI generated pipelines multiply across teams, poor data quality has become the top reported challenge for data practitioners. That problem gets worse when no one owns the output.
Treat AI as a productivity layer, not a knowledge replacement.
Building a Portfolio That Gets You Shortlisted in 2026
This is where most junior data engineer skill building goes wrong. The problem is not effort. It is direction.
What a Weak Portfolio Project Looks Like
Most fresher portfolios look the same because they come from the same tutorials.
A weak portfolio project typically:
Loads a CSV into a SQLite database
Has no orchestration or scheduling
Lives in a single Jupyter notebook with no modular code
Has no data quality checks or tests
Uses a tutorial dataset like Titanic or Iris
These projects do not signal readiness. They signal that you followed instructions.
What a Strong Portfolio Project Looks Like
A strong portfolio project:
Ingests real data from a public API (weather, e commerce, transport)
Is orchestrated with Airflow with retry logic and alerting
Is transformed using dbt with at least schema tests and source freshness checks
Is deployed on a real cloud platform (GCP, AWS, or Azure) with documented cost decisions
Answers a specific business question, like "Which product categories show the highest return rates on weekends?"
One well built project like this is worth more than five shallow ones. Depth signals production readiness. Breadth of half finished projects signals anxiety and lack of focus.
Guided project paths that simulate cloud environments, like Enqurious's Data Engineering paths, can help close the gap between tutorial work and production readiness.
How to Present Your Projects
Your GitHub README is a technical narrative. It should explain what the project does, why the architecture was designed the way it was, and what trade offs were made. An architecture diagram is a communication tool, not just a decoration.
When a hiring manager opens your project, they should be able to tell quickly that you built this yourself and that you understand what you built.
DE Interview Preparation in 2026
Junior Data Engineer Skills Tested in Fresher Interviews
For freshers, the focus is on SQL fundamentals, Python scripting, and basic pipeline design questions. Conceptual understanding of cloud services is expected but not deep expertise.
The most common mistake freshers make is over claiming tool knowledge on their resume. If your project used Spark, be ready to explain why Spark and not something simpler. If you list Kafka, expect to answer what a consumer group is.
It is not unusual for candidates with five years of SQL on their resume to freeze on basic optimization questions. The tool name on the resume is real. The depth often is not.
Mid Level DE Interview Preparation (2 to 4 Years)
Mid level interviews move quickly into system design. "Design a pipeline that ingests 10 million records per day with a 30 minute SLA" is a standard question. The expectation is that you can reason through architecture choices, not just name tools.
dbt and Airflow depth get tested directly. Interviewers want to see how you handle failure, not just success.
Common Mistakes That Cost Candidates the Offer
Listing tools without being able to defend the choice
Giving generic answers to system design questions without trade off reasoning
Having no hands on project examples to reference when pressed
Not knowing the "why" behind the architectural decisions in their own portfolio
Weak resume bullet vs strong resume bullet:
Weak: "Worked on data pipelines using Python and Airflow."
Strong: "Built an Airflow orchestrated ingestion pipeline that processed 5 million daily records from a REST API into BigQuery, with schema validation, SLA monitoring, and automatic Slack alerts on failure."
What Hiring Managers Actually Look For
Resume red flags that get you filtered quickly:
Tool lists with no project context
Certifications listed above experience
Vague descriptions like "worked on data pipelines"
Resume signals that get you shortlisted:
Specific outcomes tied to specific tools
Clear evidence of end to end project ownership
Demonstrated understanding of production concerns like failure handling and data quality
The soft skills that matter are ownership mindset, communication, and the ability to debug methodically under pressure. These show up in interviews and get discussed in hiring debriefs more than most candidates expect.
Frequently Asked Questions
Is data engineering a good career in 2026?
Yes. Demand for data engineers remains strong across industries. DE roles consistently rank among the higher paying technical positions, and the shift toward platform thinking has made the role more strategic, not less relevant.
How long does it take to become a data engineer?
With focused effort and a strong portfolio project, most people can reach a hirable baseline in 6 to 12 months, though timelines vary widely based on prior background and depth of practice. Certifications alone will not get you there. Hands on project work is what closes the gap.
What is the best cloud platform to learn for data engineering?
There is no universal answer. GCP with BigQuery is a strong starting point if you value beginner friendly tooling and dbt integration. AWS dominates enterprise data infrastructure. Azure leads in companies already on the Microsoft stack. Choose based on the companies you want to target.
Do I need a degree to get a data engineering job?
A degree helps but is not a hard requirement at most companies. What hiring managers consistently look for is a demonstrable portfolio, technical depth in the core stack, and the ability to reason through real problems in an interview.
What is the difference between a data engineer and a data analyst?
Data engineers build and maintain the infrastructure that makes data accessible. Data analysts work with that data to generate insights. In 2026, the roles are increasingly collaborative, and tools like dbt sit at the boundary between the two.
Your Next Step
The roadmap is clear. The tools are known. The gap between knowing the roadmap and having a job offer is always the same thing: you have not built anything real yet.
Certifications get attention. Projects get offers. The market rewards builders, not readers.
Your next step is not another roadmap. It is your first real project.
Ready to Experience the Future of Data?
You Might Also Like
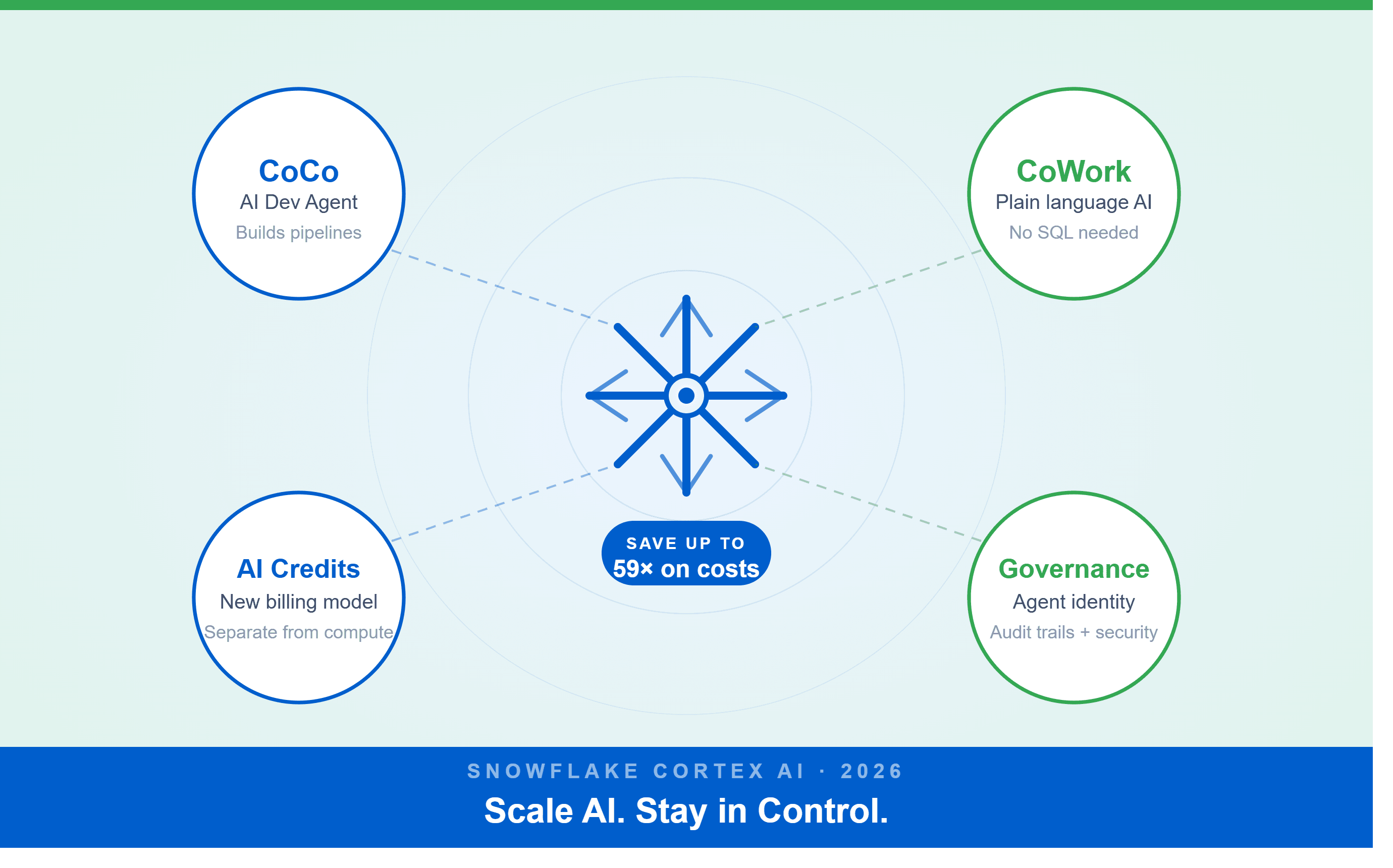
A Snowflake Summit 2026 benchmark revealed a 59x cost gap — open-source models at 440 credits vs. frontier models at 26,000 credits for identical workloads. Learn how CoCo, CoWork, AI Credits, and Cortex Training change enterprise AI strategy.
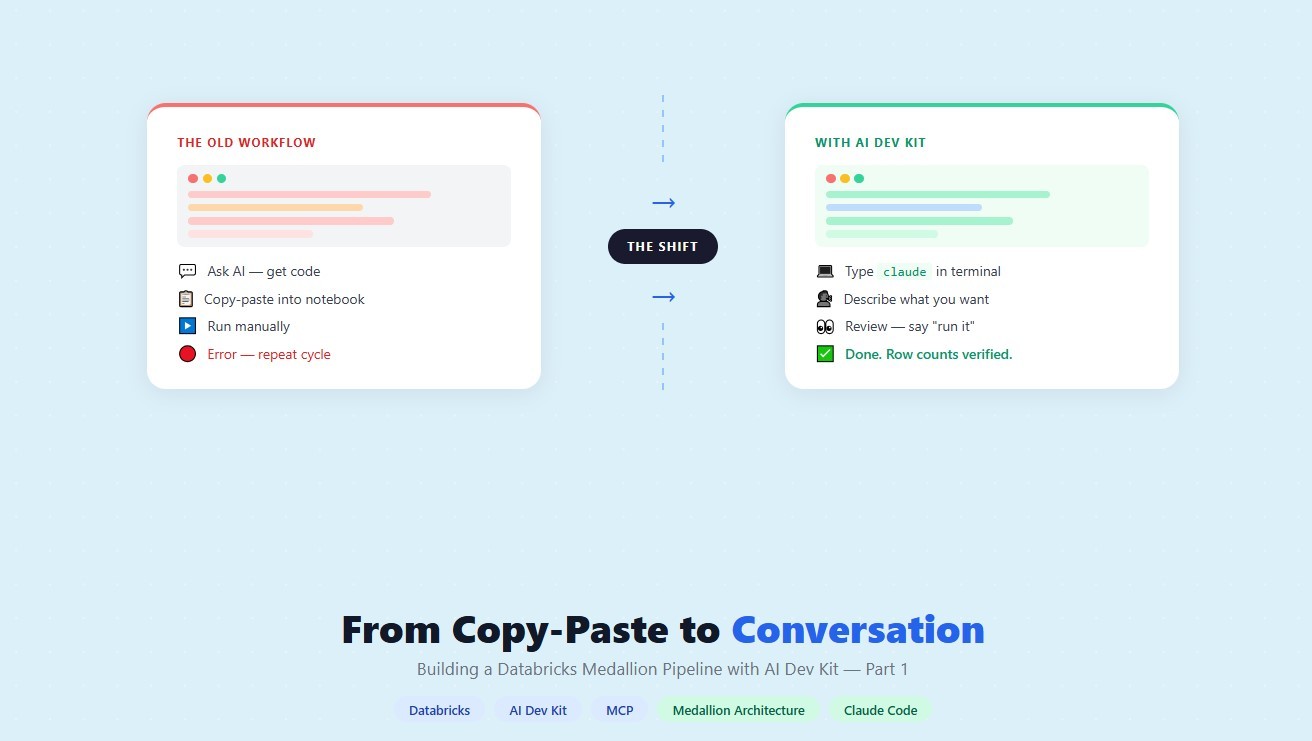
How a data engineering team replaced manual pipeline work with natural language prompts, using Claude Code and the Databricks AI Dev Kit.

Six errors, 6 hours of debugging, and the permission checklist that finally made Databricks Apps + Genie work. The full lessons-learned guide.

Your Claude Code session isn't lost. It's on disk, in a folder /resume isn't scanning. Here's how to find any session in 30 seconds, with the exact commands.

Scenario based learning replaces tutorials with realistic operational scenarios where engineers develop the hands on judgment classroom instruction cannot produce. How it works and why it matters.
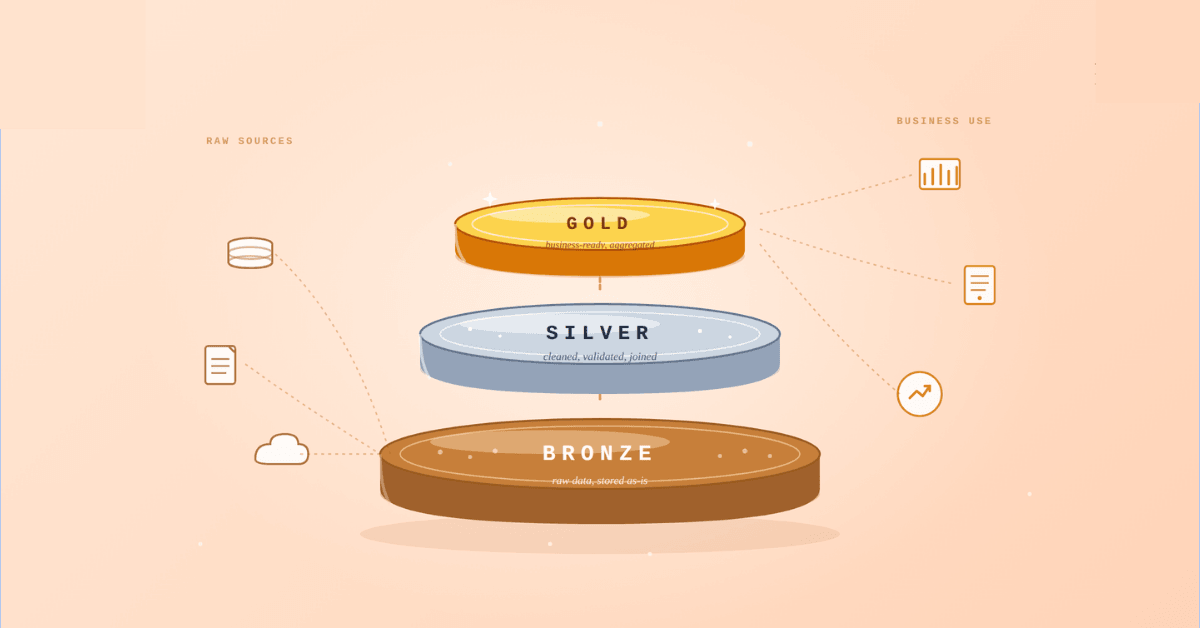
Medallion Architecture splits your data pipeline into Bronze, Silver, and Gold layers so a small business change never forces a full rebuild. Here's why it works.

I was working on a large content repository on Windows, and I needed to version some new work — campaign assets, workshop content, LinkedIn job descriptions, and some file deletions. Simple enough, right? What followed was a two-day journey through some of Git's more obscure corners.

A complete beginner’s guide to data quality, covering key challenges, real-world examples, and best practices for building trustworthy data.

Explore the power of Databricks Lakehouse, Delta tables, and modern data engineering practices to build reliable, scalable, and high-quality data pipelines."

Data doesn’t wait - and neither should your insights. This blog breaks down streaming vs batch processing and shows, step by step, how to process real-time data using Azure Databricks.

This blog talks about Databricks’ Unity Catalog upgrades -like Governed Tags, Automated Data Classification, and ABAC which make data governance smarter, faster, and more automated.

Tired of boring images? Meet the 'Jai & Veeru' of AI! See how combining Claude and Nano Banana Pro creates mind-blowing results for comics, diagrams, and more.
This blog walks you through how Databricks Connect completely transforms PySpark development workflow by letting us run Databricks-backed Spark code directly from your local IDE. From setup to debugging to best practices this Blog covers it all.
Master the bronze layer foundation of medallion architecture with COPY INTO - the command that handles incremental ingestion and schema evolution automatically. No more duplicate data, no more broken pipelines when new columns arrive. Your complete guide to production-ready raw data ingestion

This blog talks about the Power Law statistical distribution and how it explains content virality

An account of experience gained by Enqurious team as a result of guiding our key clients in achieving a 100% success rate at certifications