
What is Scenario Based Learning for Data Teams?

Ready to transform your data strategy with cutting-edge solutions?
Scenario based learning for data teams is a training methodology that replaces passive instruction with immersive, job replicated problem environments. Instead of tutorials and certifications, engineers work through realistic operational scenarios: broken pipelines, incomplete requirements, production like failure states. They develop the hands on judgment that classroom instruction cannot produce. Also referred to as simulation based learning or experiential learning for technical roles, it is the practical bridge between tool familiarity and operational readiness.
Most organizations discover this gap the hard way.
A mid sized enterprise completed a four month onboarding program for newly hired data engineers: structured learning paths, vendor certifications, weekly assessments. By the end, completion rates had hit ninety percent. Every learning objective was met.
A few weeks into their first delivery engagement, the engineering manager escalated.
The engineers could explain concepts and describe workflows fluently. They were struggling with the actual work. A production pipeline broke and sat unresolved for two days while senior engineers were repeatedly pulled in. Stakeholder requirements arrived incomplete, and the team waited, again and again, for clarity that never fully came. During a client facing technical review, basic architectural decisions could not be defended under questioning.
They said: these engineers are not ready.
The L&D team pulled the data: ninety three percent completion, certifications earned, objectives met.
Both accounts were accurate.
No one had failed to do their job. Qualified candidates were hired. A well structured program was delivered. Every module was completed. The delivery manager was simply describing what was visible on the ground.
The gap wasn't in the metrics. It surfaced only under actual delivery conditions: ambiguous requirements, live environments, real failure states, the expectation of independent judgment. Senior engineers who should have been building systems were instead walking junior colleagues through decisions those colleagues couldn't make alone. Timelines slipped without formal acknowledgment. In client facing moments, hesitation was visible in the room.
Most organizations absorb this as a cost of hiring. It isn't. It is a signal that the learning design is failing to produce what delivery actually requires.
The question is not who failed. It is, if every part of the system performed as designed, why did the outcome fall short?
Why the Data Readiness Gap Persists Even After Structured Onboarding
This pattern is not limited to new graduates.
The same gap surfaces whenever experienced professionals cross skill into unfamiliar domains:
A senior SQL analyst transitioning into cloud data engineering
A BI team migrating from a legacy stack to dbt and Databricks
A Python developer moving into MLOps
An analytics team asked to build production grade AI pipelines
The seniority changes. The domain changes. The gap appears in the same place: at the boundary between completing the program and operating independently under real conditions.
These professionals are not unqualified. They have credentials, completed programs, and tool familiarity. They can describe the architecture. They cannot operate inside it under pressure.
What this looks like organisationally is rarely dramatic. It accumulates. Senior engineers field questions they shouldn't have to field. Production decisions flow upward because no one on the junior team trusts their own judgment enough to make a call without checking first. A data quality issue that surfaces in staging sits open for a week while two senior engineers triage it between meetings, each carrying fifteen other priorities.
None of this is tracked. No ticket is filed for "required excessive senior intervention." No post mortem traces a delayed delivery to a competence gap. The cost stays invisible until a delivery manager runs out of runway to absorb it.
The average data engineering onboarding period in enterprise environments runs three to six months before a new hire reaches full productivity. Across a growing team or a tooling transformation, that window compounds. The gap is structural, a product of what the learning design systematically left out. Understanding what that is requires asking a more fundamental question about how expertise actually forms.
Why Certifications and Tutorials Don't Create Production Ready Data Engineers
The question most learning programs never seriously engage with: why do senior engineers outperform junior ones even when both know the same tools?
The answer is not memorisation. It is that senior engineers have accumulated a mental library of failure.
What Senior Engineers Have That Junior Engineers Don't
When a senior data engineer looks at a slow Snowflake query, they are not reasoning from first principles. They are pattern matching. They have seen this before, or something close enough. They know which layers to inspect first, which assumptions to challenge, which failure modes cluster together. Their diagnosis is faster because past experience compressed the decision tree.
Consider what actually happens the first time an engineer inherits a broken pipeline in production. The failure is not clean. The logs are incomplete. The error message is misleading. The original developer is unavailable. Three things could be wrong, and the engineer has to decide where to look first, knowing that each wrong hypothesis burns time, that downstream teams are waiting, that the business is asking for a status update that doesn't exist yet.
There is no answer at the bottom of the page. There is pressure, uncertainty, and the need to form a judgment under incomplete information. The wrong hypothesis, the revised mental model, the second attempt that also fails, the narrowing focus that eventually isolates the root cause: none of that is taught in a course. It is built through exposure.
The engineers who navigate it well are the ones who have been there before. They recognise the shape of the problem before they can name the cause. They know which Spark errors are symptoms and which are root causes. That recognition is not knowledge. It is accumulated experience.
What Clean Learning Environments Get Wrong
Traditional learning cannot replicate this. The environment is too clean.
In a tutorial, the dataset is prepared. The pipeline runs correctly at the end. Error messages are expected and explained. Real pipelines have schema drift. Real dashboards break because an upstream team renamed a column without notice. Real infrastructure fails in ways the documentation doesn't cover.
When learning environments strip out this friction, they strip out the mechanism through which expertise forms. A professional who has only built pipelines that work has no pattern recognition for pipelines that don't. Tutorial hell is not about content quality. It is about the absence of productive struggle. And productive struggle is exactly what transforms a learner into a practitioner.
How Scenario Based Learning Builds Real Operational Competence
Scenario based learning is not a category of content. It is a fundamentally different kind of environment, one built around the conditions that actually produce competence.
In a traditional learning environment, the learner receives information about how systems work. In a scenario based environment, the learner is inside a system that isn't working, with a deadline, no predetermined resolution path, and the expectation of independent judgment.
The Core Learning Loop in Scenario Based Training
A DAG has been failing silently for forty eight hours. Downstream tables are stale. The business team has escalated. There is no tutorial to follow, no guaranteed resolution. There is a problem, a live environment, and a timeline already slipping.
The learner forms a hypothesis. It is wrong. They debug further. Their mental model updates. They try again. Eventually they isolate the root cause, fix it, and document what they found.
That sequence is the learning. The core loop is:
Attempt → Fail → Debug → Improve → Deliver.
The scenarios are not simplified to be educational. A data engineer might be handed a dbt model producing aggregations that look correct but are silently double counting records due to a fan out join introduced upstream. The numbers are wrong, but they don't look wrong. Catching it requires SQL depth and something less codifiable: the instinct to distrust a result that feels right. That instinct is not taught. It is built through having been wrong before in the same way.
What changes is not what the learner knows. What changes is how they behave when the next failure arrives. They recognise something. They move faster. They make a judgment call without escalating. The second broken pipeline is categorically easier than the first, not because it is simpler, but because the pattern now exists, formed through experience rather than instruction.
Traditional learning produces professionals who can follow documented processes. Scenario based learning produces professionals who can navigate situations that aren't in the documentation.
How Enqurious Delivers Scenario Based Learning for Data Teams
If competence forms through repeated exposure to operational ambiguity, through failure navigated under pressure, through hypotheses revised in real time, the implication for learning design is unavoidable. The environment itself must replicate those conditions. Not describe them. Replicate them.
Most platforms are built to deliver content at scale. Replicating operational conditions requires something categorically different: authentic failure states, scenarios that resist clean resolution, and evaluation that assesses how a learner reasoned, not whether they completed.
This is what Enqurious was built as. A scenario based experiential learning platform for data and AI teams.
The scenarios are designed by practitioners who have worked inside these problems in real delivery contexts: not educational approximations, but reconstructions of actual operational situations. The upstream dependency that is poorly documented. The schema inconsistency that only appears at volume. The requirement that conflicts with the existing data model. The ambiguity is deliberate, because deliberate ambiguity is the mechanism. Learners work inside the actual tools used in real delivery environments. The friction stays inside the problem, where it belongs.
The evaluation reflects the same logic. The goal is not to measure whether a learner completed a scenario. It is to understand how they reasoned through uncertainty while solving it: where their judgment held, where it broke down, and what that reveals about operational readiness. At team level, this gives organisations visibility into how capability is actually distributed, before a production incident surfaces it for them.
Enqurious exists to give professionals production like experience before they encounter production itself. Everything else follows from that premise.
What Organisational Impact Looks Like in Practice
The team level effects of scenario based training are specific and observable.
New hires onboard faster. They arrive with pattern recognition already forming. The broken pipeline on Day 1 is not their first broken pipeline. The ambiguous stakeholder brief is not their first. They have been in those situations, not in production, but in environments built to replicate its conditions. Onboarding shortens materially because the experience the program produces is different in kind.
Senior engineers are freed to build. When junior team members can debug independently, forming a hypothesis, testing it, revising it, and arriving at a resolution without escalation, the senior engineer is freed to build. Not intermittently. Structurally. The invisible load lifts. The leverage senior engineers were hired to provide gets restored.
Teams behave differently under pressure. Incidents get resolved without the upward flow of uncertainty. Client facing moments don't produce hesitation. Architectural decisions get made and defended. The confidence is not performed. It was built through repeated experience of navigating difficulty and emerging from it.
For organisations scaling data teams, running cloud migrations, or building production AI capability, the difference between a team that functions under pressure and one that requires constant senior scaffolding is operationally significant. The gap between them is not intelligence or effort. It is exposure.
For organisations that have made this shift, the results are documented in Enqurious case studies.
The Measurable Difference Between Knowledge and Competence
There is a version of technical education that treats knowledge as the output. If the learner passes the test, the program succeeded.
There is a more demanding version that treats competence as the output. If the learner can handle the situation, the program succeeded.
The gap between these two versions is not visible in credentials. The credentials can look identical. The capability is not.
It shows up in who freezes in front of a broken pipeline and who starts diagnosing. In who waits for guidance that won't fully arrive and who forms a working hypothesis from incomplete information and moves. In who needs a senior engineer beside them to feel confident and who makes the call and owns the outcome. These are not attitude differences. They are not intelligence differences. They are the product of entirely different kinds of learning experience.
Traditional learning does what it was designed to do. It transmits knowledge efficiently. What it cannot do is replicate the conditions through which judgment forms: the ambiguity, the pressure, the absence of a predetermined answer, the consequences of being wrong. Those conditions have to be experienced. They cannot be explained into existence.
Scenario based experiential learning is the part of training most organisations have never been able to scale. Data teams that make this shift don't just onboard faster. They build institutional judgment that compounds: teams that recover from production failure without organisational drag, that make architectural decisions under pressure and defend them, that function at full capacity without constant senior oversight.
Experience creates competence. Scenario based learning creates experience. For data teams where the cost of inexperience is real and measurable, that is the argument worth acting on.
To explore what this looks like for your team, start with a conversation.
Ready to Experience the Future of Data?
You Might Also Like

89% of enterprise AI pilots never reach production. Data integration, governance gaps, and silos are why. See how Snowflake Cortex AI fixes the root cause.
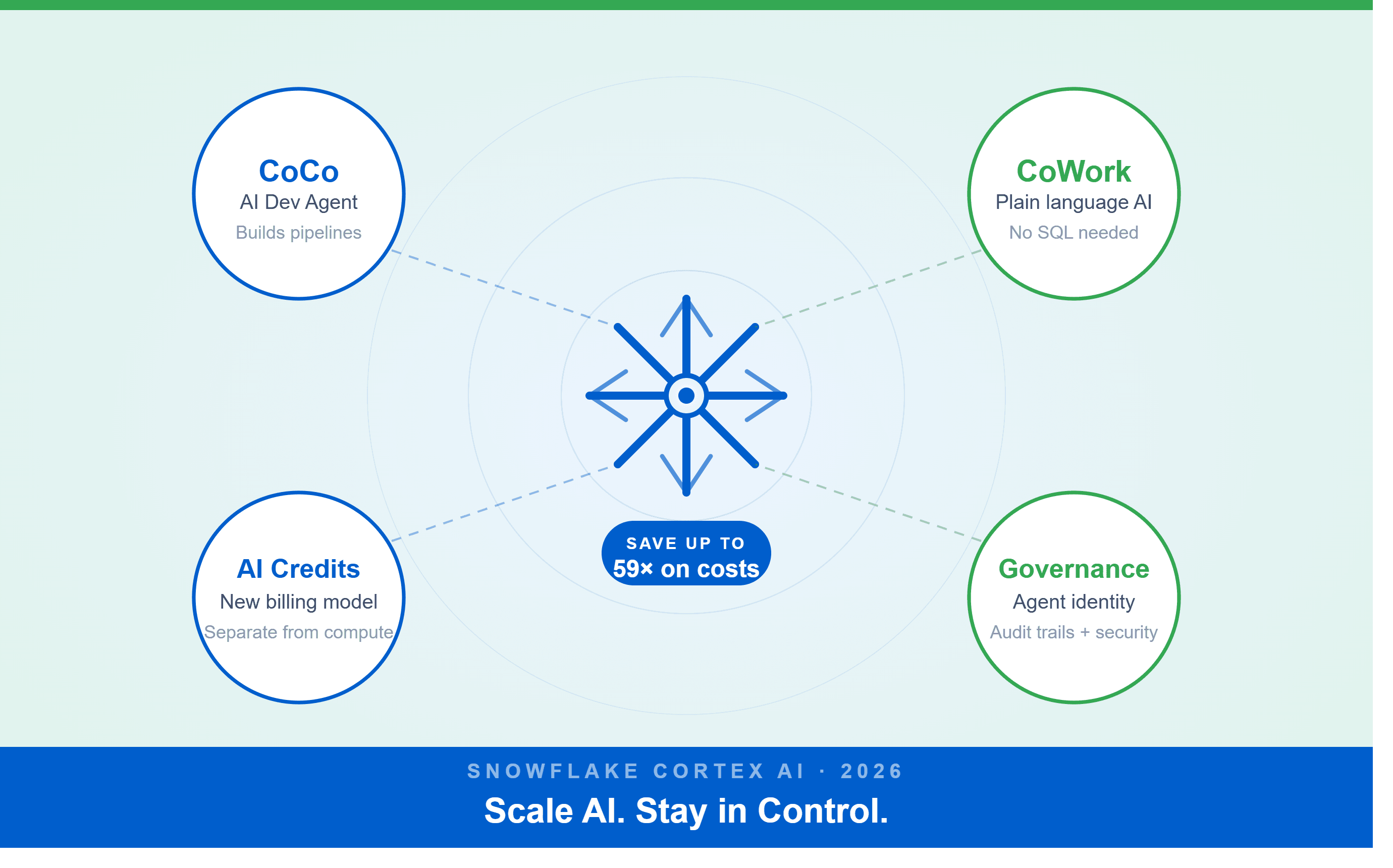
A Snowflake Summit 2026 benchmark revealed a 59x cost gap — open-source models at 440 credits vs. frontier models at 26,000 credits for identical workloads. Learn how CoCo, CoWork, AI Credits, and Cortex Training change enterprise AI strategy.
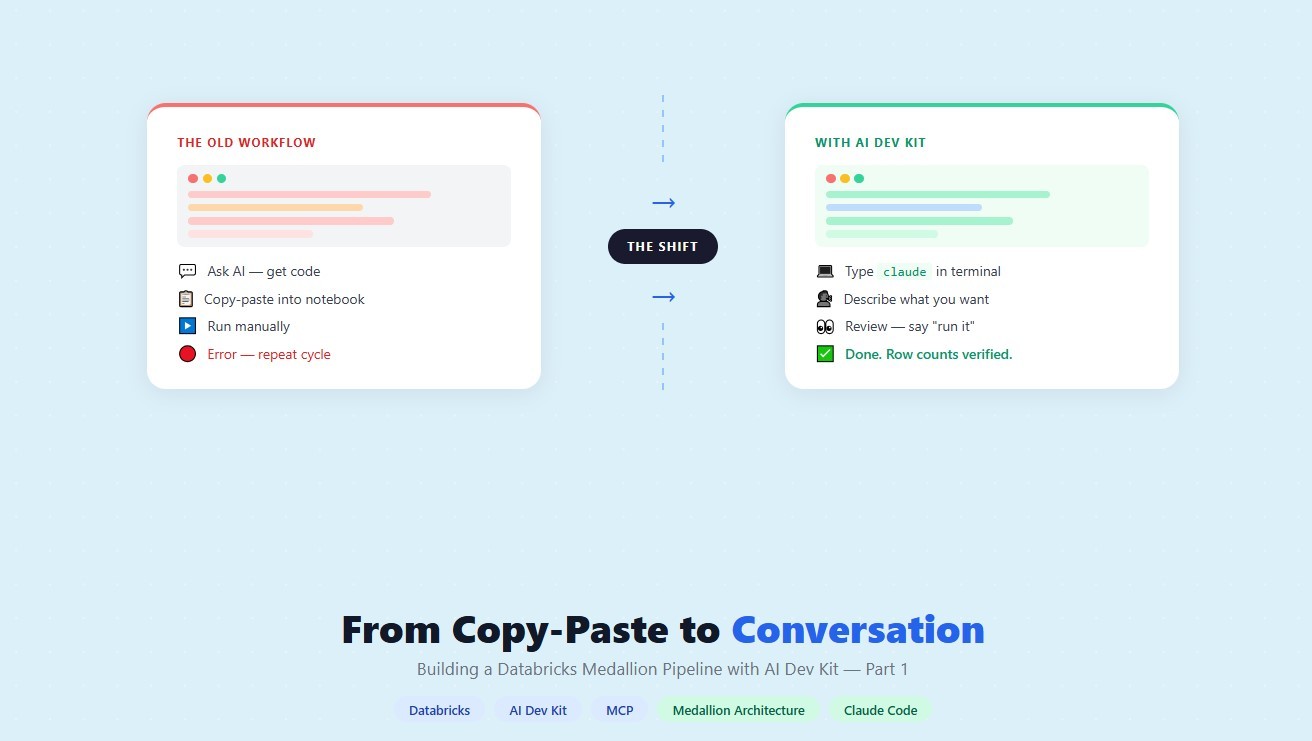
How a data engineering team replaced manual pipeline work with natural language prompts, using Claude Code and the Databricks AI Dev Kit.

Six errors, 6 hours of debugging, and the permission checklist that finally made Databricks Apps + Genie work. The full lessons-learned guide.

Your Claude Code session isn't lost. It's on disk, in a folder /resume isn't scanning. Here's how to find any session in 30 seconds, with the exact commands.
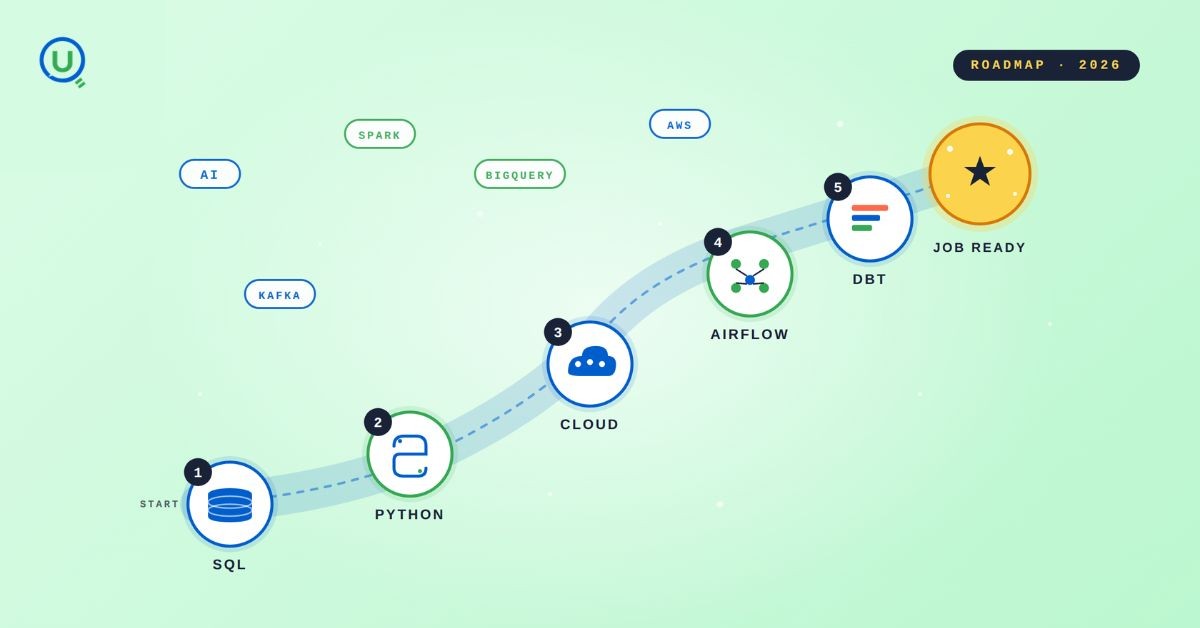
The 2026 data engineering roadmap. SQL, Python, cloud, Airflow, dbt, streaming. What companies actually hire for and how to build a portfolio that gets shortlisted.
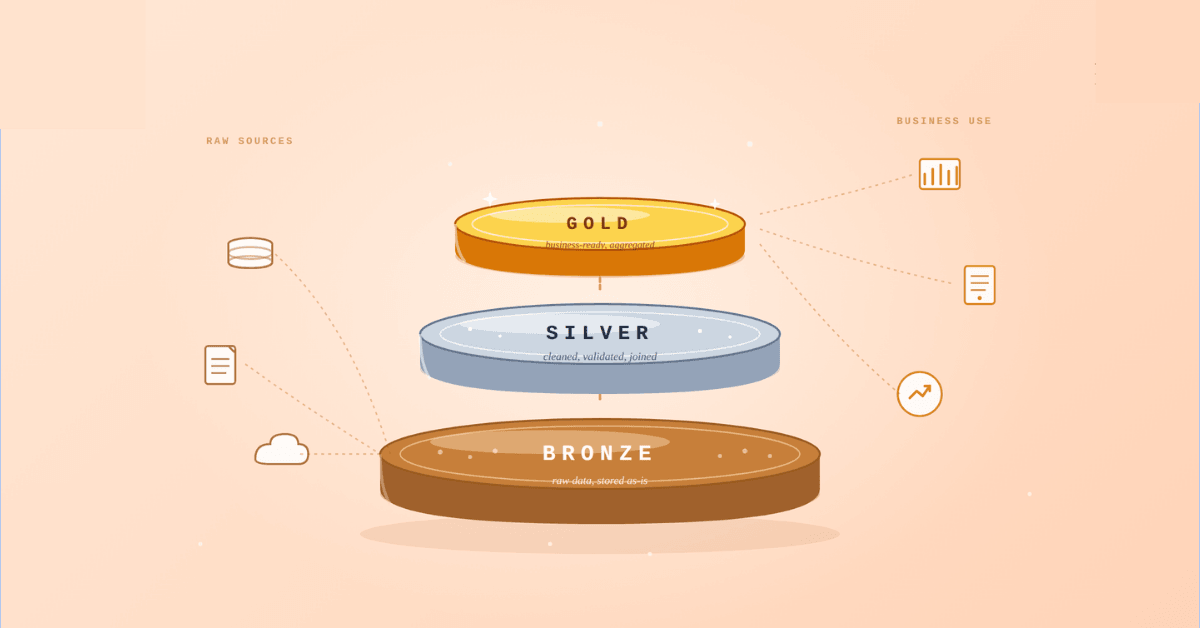
Medallion Architecture splits your data pipeline into Bronze, Silver, and Gold layers so a small business change never forces a full rebuild. Here's why it works.

I was working on a large content repository on Windows, and I needed to version some new work — campaign assets, workshop content, LinkedIn job descriptions, and some file deletions. Simple enough, right? What followed was a two-day journey through some of Git's more obscure corners.

A complete beginner’s guide to data quality, covering key challenges, real-world examples, and best practices for building trustworthy data.

Explore the power of Databricks Lakehouse, Delta tables, and modern data engineering practices to build reliable, scalable, and high-quality data pipelines."

Data doesn’t wait - and neither should your insights. This blog breaks down streaming vs batch processing and shows, step by step, how to process real-time data using Azure Databricks.

This blog talks about Databricks’ Unity Catalog upgrades -like Governed Tags, Automated Data Classification, and ABAC which make data governance smarter, faster, and more automated.

Tired of boring images? Meet the 'Jai & Veeru' of AI! See how combining Claude and Nano Banana Pro creates mind-blowing results for comics, diagrams, and more.
This blog walks you through how Databricks Connect completely transforms PySpark development workflow by letting us run Databricks-backed Spark code directly from your local IDE. From setup to debugging to best practices this Blog covers it all.
Master the bronze layer foundation of medallion architecture with COPY INTO - the command that handles incremental ingestion and schema evolution automatically. No more duplicate data, no more broken pipelines when new columns arrive. Your complete guide to production-ready raw data ingestion

This blog talks about the Power Law statistical distribution and how it explains content virality

An account of experience gained by Enqurious team as a result of guiding our key clients in achieving a 100% success rate at certifications