
Snowflake Cortex AI in 2026: 59x Cost Difference Explained
Ready to transform your data strategy with cutting-edge solutions?
Snowflake Cortex AI in 2026: The AI Revolution Nobody Told Your Budget About
What data leaders need to know before scaling Snowflake Cortex AI across the enterprise.
Key Takeaways
Snowflake Cortex AI is Snowflake's native suite of AI and machine learning functions that runs directly inside the Snowflake Data Cloud, allowing teams to build, deploy, and govern AI workflows without moving data to an external platform.
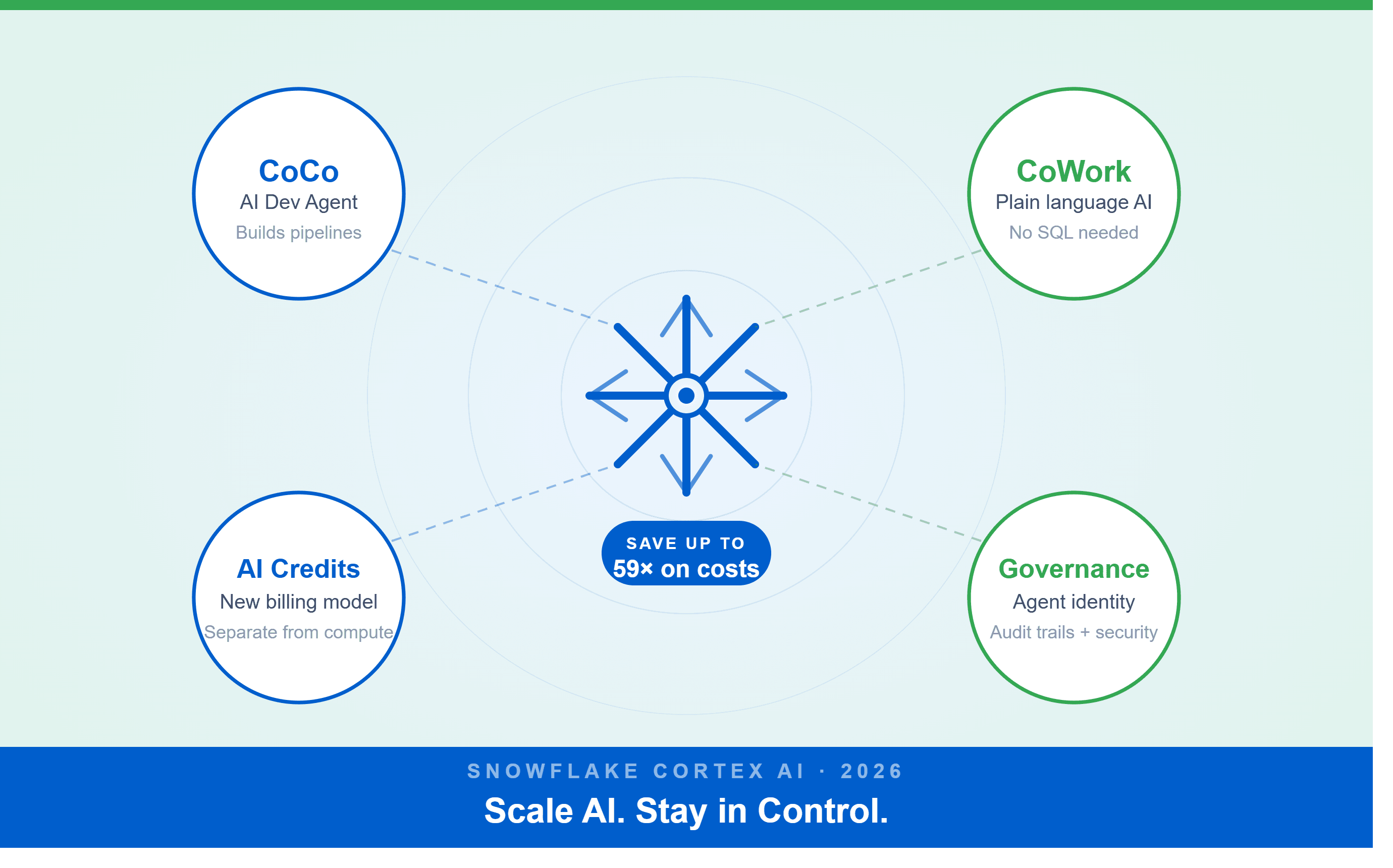
At Snowflake Summit 2026, the company made five major announcements:
CoCo (formerly Cortex Code) — an autonomous AI developer agent for data and engineering teams
CoWork (formerly Snowflake Intelligence) — a natural-language AI interface for business users powered by a semantic layer called Cortex Sense
AI Credits — a new, separate billing model for AI consumption, decoupled from traditional warehouse compute
AI Agent Governance — per-agent identity, audit trails, and AI Security Posture Management including prompt injection detection and data exfiltration monitoring
Cortex Training — the ability to train domain-specific models directly on data inside Snowflake, reducing long-term inference costs
A benchmark presented at the Summit showed the same workload consuming approximately 440 credits with an open-source model versus approximately 26,000 credits with a frontier model — a 59x cost difference for an identical business outcome.
AI Is No Longer the Expensive Experiment in the Corner
A year ago, most organizations were still asking:
"How can we use AI?"
Today, the question has changed.
"How do we scale AI without losing control of costs, governance, and security?"
That is exactly where Snowflake's 2026 announcements become interesting.
At Snowflake Summit 2026, the company unveiled a significant expansion of its AI ecosystem. New AI agents, governance capabilities, model training frameworks, and a revised billing model are transforming Snowflake from a cloud data warehouse into something much larger: an AI operating system for the enterprise.
The exciting part? You can now build AI-powered workflows directly where your data already lives — no external pipelines, no data movement, no separate AI infrastructure to manage.
The concerning part? You can also exhaust your AI budget faster than ever if you do not understand how the new billing model works.
Meet Snowflake's New AI Workforce
One of the biggest announcements at the Summit was not a single new feature. It was a new way of thinking about who — or what — does work inside the platform.
Snowflake has divided its AI strategy into two distinct user categories: AI for technical teams, and AI for everyone else.
What Is Snowflake CoCo?
CoCo (formerly Cortex Code) is Snowflake's autonomous AI developer agent, designed for engineers, analytics engineers, and data teams. The rebrand from Cortex Code to CoCo signals a deliberate shift in intent: from code completion and suggestion to autonomous, multi-step task execution.
Imagine telling an AI assistant:
"Build me a real-time customer churn dashboard and deploy the pipeline."
Instead of returning a suggestion for you to implement, CoCo can perform many of the steps itself — writing, testing, and deploying code across the workflow.
CoCo integrates across the full modern developer stack:
VS Code — inline agentic assistance inside the developer's primary editor
Slack — task delegation and status updates without leaving the communication layer
Excel — bringing data transformation capabilities to spreadsheet users
Claude Code — Anthropic's agentic coding tool, enabling AI-to-AI task handoffs
Snowflake Datastream — direct connection to real-time data pipelines
The significance of this integration list is that it covers the entire developer workflow loop — from writing and reviewing code to communicating results and streaming live data. CoCo is not a standalone tool; it is designed to sit inside workflows that already exist.
The bigger story here is not productivity. It is automation. We are moving from AI assistants that answer questions to AI agents that complete tasks.
What Is Snowflake CoWork?
CoWork (formerly Snowflake Intelligence) is Snowflake's natural-language AI interface for business users — people who need answers from data but have no SQL, BI, or technical knowledge.
Imagine a marketing manager asking:
"Show me our top-performing campaigns from the last quarter and explain why they succeeded."
No SQL. No dashboards. No analyst required.
CoWork handles this through a semantic layer called Cortex Sense, which translates organisational context — business metrics, company-specific definitions, and data relationships — into language the AI can reason over accurately.
This is where AI adoption stops being a data team initiative and becomes an enterprise-wide transformation. It is also where AI spending can quietly become dangerous, because every business user running natural-language queries is consuming AI Credits — a new billing category that most existing cost controls do not track.
The Cost Trap Most Teams Do Not See Coming
"We already monitor Snowflake warehouse costs, so AI costs must be covered too."
This is the most common misconception among organisations scaling Snowflake Cortex AI in 2026 — and it is incorrect.
Snowflake introduced AI Credits as a separate billing model in 2026. AI consumption is now fully decoupled from traditional warehouse compute credits. That means resource monitors configured against compute usage will not alert you when AI spend spikes.
Consider what this looks like in practice:
A team of 50 business users each runs ten CoWork queries per day. That is 500 AI-powered requests daily — none of which appear in your warehouse cost report.
A data engineer experiments with large language model calls during development. Each iteration consumes AI Credits invisibly.
A customer-facing chatbot built on Cortex functions goes viral internally. Usage triples in a week. No automated alert fires.
In each scenario, your warehouse bill remains stable. Your AI bill grows unchecked.
This is why AI cost governance is no longer a best practice. It is financial infrastructure — as fundamental to your Snowflake setup as access controls and role-based permissions.
Why Model Selection Is Now a Budget Decision
The most striking insight from Snowflake Summit 2026 was not a product announcement. It was a cost benchmark.
A team executed the same workload using two different model types available inside Snowflake Cortex AI.
Benchmark: Same workload, two models (Snowflake Summit 2026)
Model Type | Credits Consumed |
|---|---|
Frontier Model | ~26,000 credits |
Open-Source Model | ~440 credits |
Same business outcome. 59x difference in cost.
For years, model selection conversations in enterprise data teams have centred on three dimensions: accuracy, latency, and capability. In 2026, there is a fourth dimension that must sit alongside the other three: cost efficiency.
Not every task requires the most capable model available. Several high-volume, low-ambiguity workloads are strong candidates for smaller, cheaper open-source models:
Classification — categorising records, tickets, or transactions into predefined buckets
Sentiment analysis — scoring customer feedback, reviews, or support conversations
Document tagging — applying metadata labels to unstructured content at scale
Simple summarisation — condensing structured reports or templated documents
The rule of thumb: tasks with high repetition, low ambiguity, and predictable output formats are your first optimization targets. Reserve frontier models for tasks where reasoning depth, nuance, or open-ended generation genuinely changes the quality of the outcome.
The organizations winning with AI in 2026 are not necessarily using the most powerful models. They are using the right model for each task — and the difference in cost is not marginal. It is 59x.
Governance Is Finally Catching Up to AI
Every organization wants AI at scale. Every security and compliance team is worried about what that means in practice.
Snowflake's 2026 governance framework addresses this with two distinct capabilities built around identity and accountability.
What Is Snowflake AI Agent Identity?
Every AI agent in Snowflake now receives its own identity — separate from the user who created or invoked it. This is a meaningful architectural shift.
Previously, when an AI agent took an action inside a data platform, that action was attributed to the human user account that initiated the session. In Snowflake's new model, agents operate under their own identity, which enables:
Separate permissions — agents are granted only the access they need, independent of the invoking user's broader permissions
Independent audit trails — every action an agent takes is logged under the agent's identity, not the user's, enabling precise accountability
Fine-grained access controls — data access policies can be applied directly to agent identities
Cleaner compliance reporting — audit logs are no longer a mix of human and machine actions
Snowflake's governance model now treats AI agents as first-class citizens in enterprise security architecture — a critical step for organisations operating under regulatory frameworks like GDPR, HIPAA, or SOC 2.
What Is Snowflake AI Security Posture Management?
AI Security Posture Management is Snowflake's new monitoring layer that applies application-level security practices to AI-specific risk vectors.
This includes detection and monitoring for:
Prompt injection — attempts to manipulate AI agent behaviour through malicious input
Data exfiltration — monitoring for AI-driven access patterns that could indicate data leaving the platform
Security alerts — real-time notifications for anomalous AI activity
Context-aware investigations — the ability to trace a security incident back through the AI interaction chain to its source
In plain terms: your organisation can now monitor AI risks with the same rigour it applies to application and infrastructure risks. This removes one of the most significant barriers to enterprise-scale AI adoption — the inability to answer "what is the AI actually doing, and who is responsible if something goes wrong?"
The Most Important SQL Query You Should Run This Week
If your organisation is already using Snowflake Cortex AI functions, this is where to start before launching any new AI initiative.
What does this query do? It surfaces your AI credit consumption by model and function for the past 30 days, ordered by the highest spend first — giving you an immediate view of where optimisation opportunities exist.
SELECT
DATE_TRUNC('day', START_TIME) AS usage_date,
FUNCTION_NAME,
MODEL_NAME,
SUM(CREDITS) AS total_credits,
SUM(TOKENS) AS total_tokens
FROM SNOWFLAKE.ACCOUNT_USAGE.CORTEX_AI_FUNCTIONS_USAGE_HISTORY
WHERE START_TIME >= DATEADD('day', -30, CURRENT_TIMESTAMP())
GROUP BY 1, 2, 3
ORDER BY total_credits DESC;
You cannot optimise what you cannot see.
This query immediately answers three questions:
Which models are consuming the most credits?
Which Cortex functions drive the highest spend?
Where is the gap between what you expected and what you are actually consuming?
What to look for: If a single function or model accounts for more than 30% of your total AI credit consumption, that is your first optimisation target. Cross-reference that function against the model selection guidance above — there is a reasonable chance it is a high-volume, low-ambiguity task running on a frontier model when an open-source alternative would deliver the same outcome.
Run this query before your next AI initiative. Make it part of your monthly data platform review.
The Next Big Announcement: Snowflake Cortex Training
One announcement from the Summit received less attention than it deserved.
What is Snowflake Cortex Training? Cortex Training is Snowflake's capability for organisations to train domain-specific AI models using their own data — entirely within the Snowflake platform, without moving data to an external training environment.
The core argument for Cortex Training over standard inference is threefold. First, domain-specific models trained on your organisation's own data can outperform general-purpose frontier models on tasks specific to your business — not because they are larger, but because they understand your vocabulary, data structure, and use cases. Second, once trained, inference on a smaller, specialised model costs significantly less than repeated calls to a large frontier model. Third, because training and inference happen inside Snowflake, data never leaves the governance boundary — which matters significantly for regulated industries.
The industries with the most to gain are those where the same types of questions are asked repeatedly against proprietary datasets:
Healthcare — clinical note classification, diagnosis coding, care pathway analysis
Financial services — transaction categorisation, credit risk assessment, regulatory document parsing
Retail — demand forecasting, product attribute extraction, customer intent classification
Manufacturing — defect detection from inspection reports, maintenance log analysis, supply chain risk tagging
Today, Cortex Training is an advanced capability. Within two to three years, as inference costs become a board-level line item for AI-heavy organisations, training domain-specific models inside the data platform may become the default strategy rather than the exception.
Five Things Every Data Leader Should Do Right Now
1. Audit Your Current AI Credit Usage
Run the SQL query from the previous section. Understand which models and functions are consuming the most credits before making any new AI investment decisions. If you cannot answer "where is our AI spend going?" you are not ready to scale AI.
2. Set User-Level and Team-Level AI Budgets
Do not wait for an unexpected invoice to drive the conversation. Define a credit ceiling per user or per team before your next AI rollout. Map those budgets to business justification — a data science team experimenting with LLM fine-tuning has a fundamentally different cost profile than a marketing team running sentiment analysis. Treat AI credit allocation the same way you would treat cloud compute budgets: owned, forecasted, and reviewed monthly.
3. Right-Size Your Model Selection
Audit the functions you are already running. For each one, ask: does this task require reasoning depth, or does it require consistency at scale? High-volume, low-ambiguity tasks — classification, tagging, simple summarisation — should be evaluated against open-source alternatives before defaulting to frontier models. The 59x benchmark is not an edge case. It is the starting point for every optimisation conversation.
4. Implement Agent Governance Before You Scale
Retrofitting security controls onto a production AI system is significantly harder than designing them upfront. Before deploying CoWork or CoCo to a broad user base, define your agent identity framework, set access control policies per agent, and configure AI Security Posture Management alerts. The organisations that will have governance problems in 2027 are the ones skipping this step in 2026.
5. Treat AI as a Product, Not a Feature
AI now demands the same operational rigour as any other critical platform. That means ownership (a named DRI for AI governance), monitoring (credit consumption dashboards reviewed regularly), budgeting (forecasted AI spend as part of platform cost planning), and a deprecation strategy (what happens when a model version changes or a Cortex function is updated). Without this infrastructure, AI scales chaotically.
Final Thoughts
The biggest lesson from Snowflake Summit 2026 is not that AI is becoming more capable.
That was already known.
The real story is that AI is becoming operational. It is moving out of experimentation and into production infrastructure — and that transition changes what it means to succeed with AI in the enterprise.
Success is no longer determined by who has access to the most powerful model. It is determined by who can balance innovation with governance, capability with cost discipline, and speed with security.
Snowflake's 2026 Cortex ecosystem gives organisations the tools to do exactly that. But the tools only work if the strategy is in place to use them intentionally.
The organisations that win over the next few years will not be the ones that use the most AI. They will be the ones that understand where AI creates value — and where it quietly creates costs.
That is the more important conversation. And it starts now.
Quick Reference Glossary
Snowflake Cortex AI — Snowflake's native suite of AI and ML functions running directly inside the Snowflake Data Cloud. Enables teams to build, deploy, and govern AI workflows without moving data to an external platform.
CoCo — Snowflake's autonomous AI developer agent (formerly Cortex Code). Designed for engineers and data teams; capable of executing multi-step technical tasks including pipeline building, code deployment, and workflow automation.
CoWork — Snowflake's natural-language AI interface for business users (formerly Snowflake Intelligence). Allows non-technical users to query data and receive answers in plain language using a semantic layer called Cortex Sense.
Cortex Sense — The semantic layer powering CoWork. Translates organisational context, business metrics, and data definitions into AI-understandable structures for accurate natural-language querying.
AI Credits — Snowflake's separate billing unit for AI and LLM consumption, introduced in 2026. Decoupled from traditional warehouse compute credits and not tracked by standard resource monitors.
AI Agent Identity — Snowflake's governance capability that assigns each AI agent its own identity, permissions, and audit trail, independent of the user who invoked it.
AI Security Posture Management — Snowflake's AI-specific monitoring layer covering prompt injection detection, data exfiltration monitoring, security alerts, and context-aware investigation of AI activity.
Cortex Training — Snowflake's capability for training domain-specific AI models on proprietary data inside the Snowflake platform, reducing long-term inference costs and improving accuracy on organisation-specific tasks.
Frontier Model — A large, state-of-the-art AI model (such as those from Anthropic, OpenAI, or Google) with broad capabilities but higher per-token inference cost.
Open-Source Model — A smaller, publicly available AI model with lower inference cost, often well-suited for high-volume, low-ambiguity tasks where reasoning depth is not required.
Ready to Experience the Future of Data?
You Might Also Like
How a data engineering team replaced manual pipeline work with natural language prompts, using Claude Code and the Databricks AI Dev Kit.

Six errors, 6 hours of debugging, and the permission checklist that finally made Databricks Apps + Genie work. The full lessons-learned guide.

Your Claude Code session isn't lost. It's on disk, in a folder /resume isn't scanning. Here's how to find any session in 30 seconds, with the exact commands.

Scenario based learning replaces tutorials with realistic operational scenarios where engineers develop the hands on judgment classroom instruction cannot produce. How it works and why it matters.
The 2026 data engineering roadmap. SQL, Python, cloud, Airflow, dbt, streaming. What companies actually hire for and how to build a portfolio that gets shortlisted.
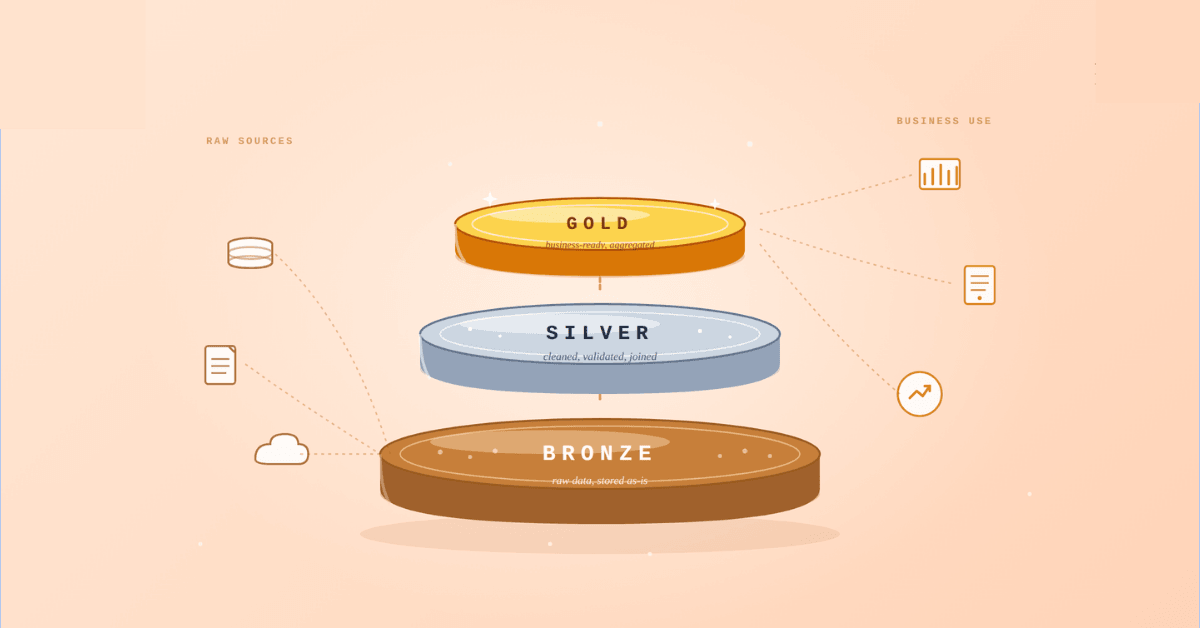
Medallion Architecture splits your data pipeline into Bronze, Silver, and Gold layers so a small business change never forces a full rebuild. Here's why it works.

I was working on a large content repository on Windows, and I needed to version some new work — campaign assets, workshop content, LinkedIn job descriptions, and some file deletions. Simple enough, right? What followed was a two-day journey through some of Git's more obscure corners.

A complete beginner’s guide to data quality, covering key challenges, real-world examples, and best practices for building trustworthy data.

Explore the power of Databricks Lakehouse, Delta tables, and modern data engineering practices to build reliable, scalable, and high-quality data pipelines."

Data doesn’t wait - and neither should your insights. This blog breaks down streaming vs batch processing and shows, step by step, how to process real-time data using Azure Databricks.

This blog talks about Databricks’ Unity Catalog upgrades -like Governed Tags, Automated Data Classification, and ABAC which make data governance smarter, faster, and more automated.

Tired of boring images? Meet the 'Jai & Veeru' of AI! See how combining Claude and Nano Banana Pro creates mind-blowing results for comics, diagrams, and more.
This blog walks you through how Databricks Connect completely transforms PySpark development workflow by letting us run Databricks-backed Spark code directly from your local IDE. From setup to debugging to best practices this Blog covers it all.
Master the bronze layer foundation of medallion architecture with COPY INTO - the command that handles incremental ingestion and schema evolution automatically. No more duplicate data, no more broken pipelines when new columns arrive. Your complete guide to production-ready raw data ingestion

This blog talks about the Power Law statistical distribution and how it explains content virality

An account of experience gained by Enqurious team as a result of guiding our key clients in achieving a 100% success rate at certifications